
Publications
Visual landmark recognition from Internet photo collections: A large-scale evaluation
In this paper, we present an object-centric, fixeddimensional 3D shape representation for robust matching of partially observed object shapes, which is an important component for object categorization from 3D data. A main problem when working with RGB-D data from stereo, Kinect, or laser sensors is that the 3D information is typically quite noisy. For that reason, we accumulate shape information over time and register it in a common reference frame. Matching the resulting shapes requires a strategy for dealing with partial observations. We therefore investigate several distance functions and kernels that implement different such strategies and compare their matching performance in quantitative experiments. We show that the resulting representation achieves good results for a large variety of vision tasks, such as multi-class classification, person orientation estimation, and articulated body pose estimation, where robust 3D shape matching is essential.
Biternion Nets: Continuous Head Pose Regression from Discrete Training Labels

TL;DR: By doing the obvious thing of encoding an angle φ as (cos φ, sin φ), we can do cool things and simplify data labeling requirements.
While head pose estimation has been studied for some time, continuous head pose estimation is still an open problem. Most approaches either cannot deal with the periodicity of angular data or require very fine-grained regression labels. We introduce biternion nets, a CNN-based approach that can be trained on very coarse regression labels and still estimate fully continuous 360° head poses. We show state-of-the-art results on several publicly available datasets. Finally, we demonstrate how easy it is to record and annotate a new dataset with coarse orientation labels in order to obtain continuous head pose estimates using our biternion nets.
» Show BibTeX
@inproceedings{Beyer2015BiternionNets,
author = {Lucas Beyer and Alexander Hermans and Bastian Leibe},
title = {Biternion Nets: Continuous Head Pose Regression from Discrete Training Labels},
booktitle = {Pattern Recognition},
publisher = {Springer},
series = {Lecture Notes in Computer Science},
volume = {9358},
pages = {157-168},
year = {2015},
isbn = {978-3-319-24946-9},
doi = {10.1007/978-3-319-24947-6_13},
ee = {http://lucasb.eyer.be/academic/biternions/biternions_gcpr15.pdf},
}
A Fixed-Dimensional 3D Shape Representation for Matching Partially Observed Objects in Street Scenes
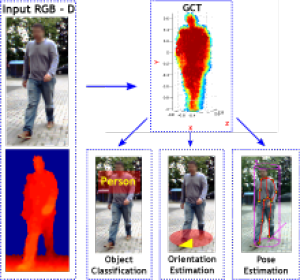
In this paper, we present an object-centric, fixeddimensional 3D shape representation for robust matching of partially observed object shapes, which is an important component for object categorization from 3D data. A main problem when working with RGB-D data from stereo, Kinect, or laser sensors is that the 3D information is typically quite noisy. For that reason, we accumulate shape information over time and register it in a common reference frame. Matching the resulting shapes requires a strategy for dealing with partial observations. We therefore investigate several distance functions and kernels that implement different such strategies and compare their matching performance in quantitative experiments. We show that the resulting representation achieves good results for a large variety of vision tasks, such as multi-class classification, person orientation estimation, and articulated body pose estimation, where robust 3D shape matching is essential.
Multi-band Hough Forests for Detecting Humans with Reflective Safety Clothing from Mobile Machinery
We address the problem of human detection from heavy mobile machinery and robotic equipment operating at industrial working sites. Exploiting the fact that workers are typically obliged to wear high-visibility clothing with reflective markers, we propose a new recognition algorithm that specifically incorporates the highly discriminative features of the safety garments in the detection process. Termed Multi-band Hough Forest, our detector fuses the input from active near-infrared (NIR) and RGB color vision to learn a human appearance model that not only allows us to detect and localize industrial workers, but also to estimate their body orientation. We further propose an efficient pipeline for automated generation of training data with high-quality body part annotations that are used in training to increase detector performance. We report a thorough experimental evaluation on challenging image sequences from a real-world production environment, where persons appear in a variety of upright and non-upright body positions.
Fixing WTFs: Detecting Image Matches caused by Watermarks, Timestamps, and Frames in Internet Photos
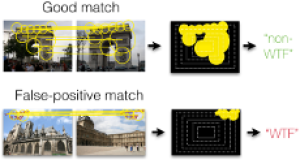
An increasing number of photos in Internet photo collections comes with watermarks, timestamps, or frames (in the following called WTFs) embedded in the image content. In image retrieval, such WTFs often cause false-positive matches. In image clustering, these false-positive matches can cause clusters of different buildings to be joined into one. This harms applications like landmark recognition or large-scale structure-from-motion, which rely on clean building clusters. We propose a simple, but highly effective detector for such false-positive matches. Given a matching image pair with an estimated homography, we first determine similar regions in both images. Exploiting the fact that WTFs typically appear near the border, we build a spatial histogram of the similar regions and apply a binary classifier to decide whether the match is due to a WTF. Based on a large-scale dataset of WTFs we collected from Internet photo collections, we show that our approach is general enough to recognize a large variety of watermarks, timestamps, and frames, and that it is efficient enough for largescale applications. In addition, we show that our method fixes the problems that WTFs cause in image clustering applications. The source code is publicly available and easy to integrate into existing retrieval and clustering systems.
Disentangling the Impact of Social Groups on Response Times and Movement Dynamics in Evacuations

Crowd evacuations are paradigmatic examples for collective behaviour, as interactions between individuals lead to the overall movement dynamics. Approaches assuming that all individuals interact in the same way have significantly improved our understanding of pedestrian crowd evacuations. However, this scenario is unlikely, as many pedestrians move in social groups that are based on friendship or kinship. We test how the presence of social groups affects the egress time of individuals and crowds in a representative crowd evacuation experiment. Our results suggest that the presence of social groups increases egress times and that this is largely due to differences at two stages of evacuations. First, individuals in social groups take longer to show a movement response at the start of evacuations, and, second, they take longer to move into the vicinity of the exits once they have started to move towards them. Surprisingly, there are no discernible time differences between the movement of independent individuals and individuals in groups directly in front of the exits. We explain these results and discuss their implications. Our findings elucidate behavioural differences between independent individuals and social groups in evacuations. Such insights are crucial for the control of crowd evacuations and for planning mass events.
Person Attribute Recognition with a Jointly-trained Holistic CNN Model
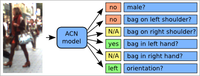
This paper addresses the problem of human visual attribute recognition, i.e., the prediction of a fixed set of semantic attributes given an image of a person. Previous work often considered the different attributes independently from each other, without taking advantage of possible dependencies between them. In contrast, we propose a method to jointly train a CNN model for all attributes that can take advantage of those dependencies, considering as input only the image without additional external pose, part or context information. We report detailed experiments examining the contribution of individual aspects, which yields beneficial insights for other researchers. Our holistic CNN achieves superior performance on two publicly available attribute datasets improving on methods that additionally rely on pose-alignment or context. To support further evaluations, we present a novel dataset, based on realistic outdoor video sequences, that contains more than 27,000 pedestrians annotated with 10 attributes. Finally, we explore design options to embrace the N/A labels inherently present in this task.
@InProceedings{PARSE27k,
author = {Patrick Sudowe and Hannah Spitzer and Bastian Leibe},
title = {{Person Attribute Recognition with a Jointly-trained Holistic CNN Model}},
booktitle = {ICCV'15 ChaLearn Looking at People Workshop},
year = {2015},
}
A Semantic Occlusion Model for Human Pose Estimation from a Single Depth image

Human pose estimation from depth data has made significant progress in recent years and commercial sensors estimate human poses in real-time. However, state-of-theart methods fail in many situations when the humans are partially occluded by objects. In this work, we introduce a semantic occlusion model that is incorporated into a regression forest approach for human pose estimation from depth data. The approach exploits the context information of occluding objects like a table to predict the locations of occluded joints. In our experiments on synthetic and real data, we show that our occlusion model increases the joint estimation accuracy and outperforms the commercial Kinect 2 SDK for occluded joints.
Sequence-Level Object Candidates Based on Saliency for Generic Object Recognition on Mobile Systems

In this paper, we propose a novel approach for generating generic object candidates for object discovery and recognition in continuous monocular video. Such candidates have recently become a popular alternative to exhaustive window-based search as basis for classification. Contrary to previous approaches, we address the candidate generation problem at the level of entire video sequences instead of at the single image level. We propose a processing pipeline that starts from individual region candidates and tracks them over time. This enables us to group candidates for similar objects and to automatically filter out inconsistent regions. For generating the per-frame candidates, we introduce a novel multi-scale saliency approach that achieves a higher per-frame recall with fewer candidates than current state-of-the-art methods. Taken together, those two components result in a significant reduction of the number of object candidates compared to frame level methods, while keeping a consistently high recall.
Robust Marker-Based Tracking for Measuring Crowd Dynamics

We present a system to conduct laboratory experiments with thousands of pedestrians. Each participant is equipped with an individual marker to enable us to perform precise tracking and identification. We propose a novel rotation invariant marker design which guarantees a minimal Hamming distance between all used codes. This increases the robustness of pedestrian identification. We present an algorithm to detect these markers, and to track them through a camera network. With our system we are able to capture the movement of the participants in great detail, resulting in precise trajectories for thousands of pedestrians. The acquired data is of great interest in the field of pedestrian dynamics. It can also potentially help to improve multi-target tracking approaches, by allowing better insights into the behaviour of crowds.
Methodology for Generating Individualized Trajectories from Experiments

Traffic research has reached a point where trajectories are available for microscopic analysis. The next step will be trajectories which are connected to human factors, i.e information about the agent. The first step in pedestrian dynamics has been done using video recordings to generate precise trajectories. We go one step further and present two experiments for which ID markers are used to produce individualized trajectories: a large-scale experiment on pedestrian dynamics and an experiment on single-file bicycle traffic. The camera set-up has to be carefully chosen when using ID markers. It has to facilitate reading out the markers, while at the same time being able to capture the whole experiment. We propose two set-ups to address this problem and report on experiments conducted with these set-ups.
Efficient Dense Rigid-Body Motion Segmentation and Estimation in RGB-D Video

Motion is a fundamental grouping cue in video. Many current approaches to motion segmentation in monocular or stereo image sequences rely on sparse interest points or are dense but computationally demanding. We propose an efficient expectation-maximization (EM) framework for dense 3D segmentation of moving rigid parts in RGB-D video. Our approach segments images into pixel regions that undergo coherent 3D rigid-body motion. Our formulation treats background and foreground objects equally and poses no further assumptions on the motion of the camera or the objects than rigidness. While our EM-formulation is not restricted to a specific image representation, we supplement it with efficient image representation and registration for rapid segmentation of RGB-D video. In experiments, we demonstrate that our approach recovers segmentation and 3D motion at good precision.
@string{ijcv="International Journal of Computer Vision"}
@article{stueckler-ijcv15,
author = {J. Stueckler and S. Behnke},
title = {Efficient Dense Rigid-Body Motion Segmentation and Estimation in RGB-D Video},
journal = ijcv,
month = jan,
year = {2015},
doi = {10.1007/s11263-014-0796-3},
publisher = {Springer US},
}
NimbRo Explorer: Semi-Autonomous Exploration and Mobile Manipulation in Rough Terrain

Fully autonomous exploration and mobile manipulation in rough terrain are still beyond the state of the art—robotics challenges and competitions are held to facilitate and benchmark research in this direction. One example is the DLR SpaceBot Cup 2013, for which we developed an integrated robot system to semi-autonomously perform planetary exploration and manipulation tasks. Our robot explores, maps, and navigates in previously unknown, uneven terrain using a 3D laser scanner and an omnidirectional RGB-D camera. We developed manipulation capabilities for object retrieval and pick-and-place tasks. Many parts of the mission can be performed autonomously. In addition, we developed teleoperation interfaces on different levels of shared autonomy which allow for specifying missions, monitoring mission progress, and on-the-fly reconfiguration. To handle network communication interruptions and latencies between robot and operator station, we implemented a robust network layer for the middleware ROS. The integrated system has been demonstrated at the DLR SpaceBot Cup 2013. In addition, we conducted systematic experiments to evaluate the performance of our approaches.
» Show BibTeX
@article{stueckler15_jfr_explorer,
author={J. Stueckler and M. Schwarz and M. Schadler and A. Topalidou-Kyniazopoulou and S. Behnke},
title={NimbRo Explorer: Semi-Autonomous Exploration and Mobile Manipulation in Rough Terrain},
journal={Journal of Field Robotics},
note={published online},
year={2015},
}
Pedestrian Line Counting by Probabilistic Combination of Flow and Appearance Information
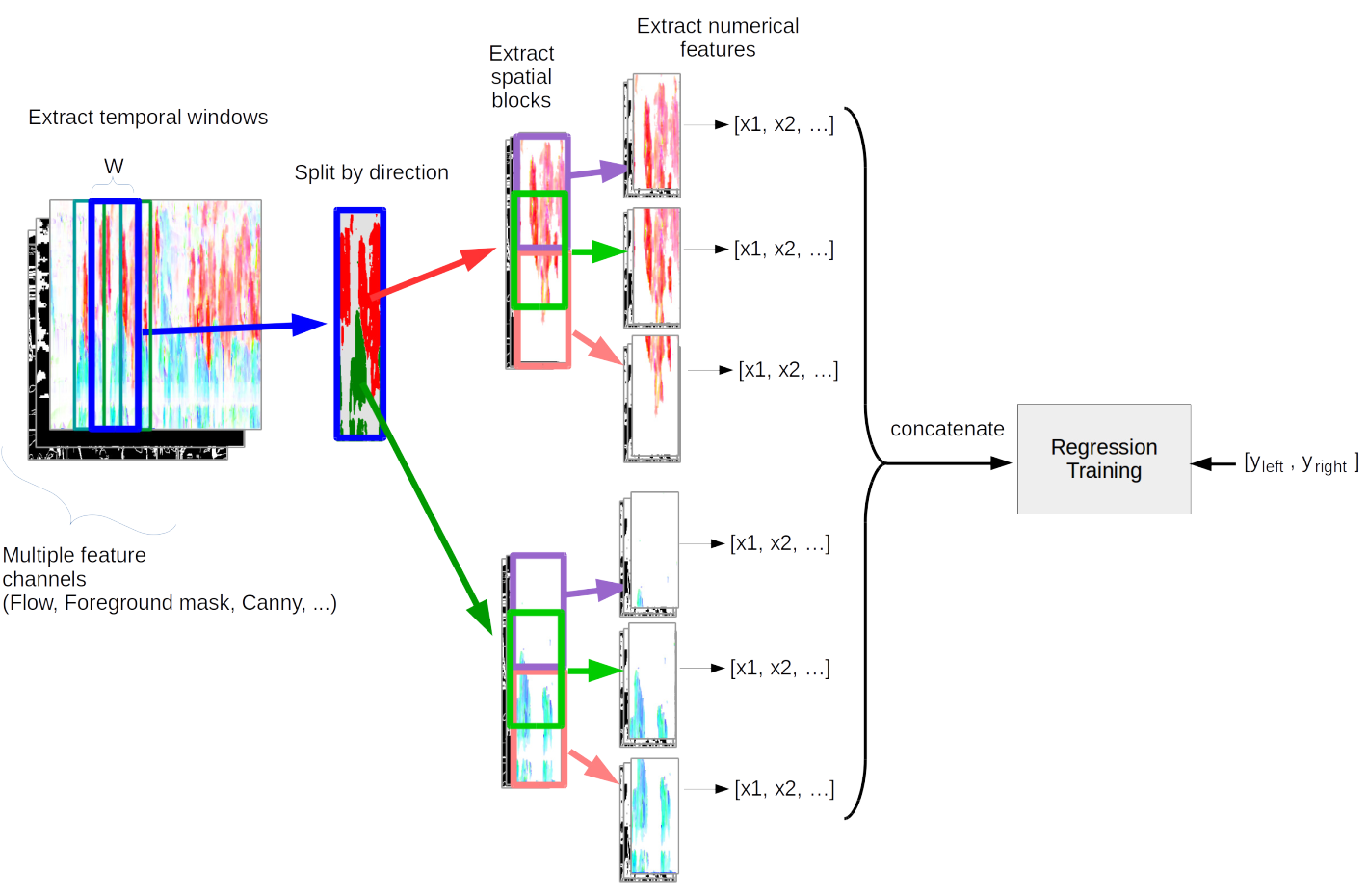
In this thesis we examine the task of estimating how many pedestrians cross a given line in a surveillance video, in the presence of high occlusion and dense crowds. We show that a prior, blob-based pedestrian line counting method fails on our newly annotated private dataset, which is more challenging than those used in the literature.
We propose a new spatiotemporal slice-based method that works with simple low-level features based on optical flow, background subtraction and edge detection and show that it produces good results on the new dataset. Furthermore, presumably due to the very simple and general nature of the features we use, the method also performs well on the popular UCSD vidd dataset without additional hyperparameter tuning, showing the robustness of our approach.
We design new evaluation measures that generalize the precision and recall used in information retrieval and binary classification to continuous, instantaneous pedestrian flow estimations and we argue that they are better suited to this task than currently used measures.
We also consider the relations between pedestrian region counting and line counting by comparing the output of a region counting method with the counts that we derive from line counting. Finally we show a negative result, where a probabilistic method for combining line and region counter outputs does not lead to the hoped result of mutually improved counters.
Sequence-Discriminative Training of Recurrent Neural Networks
We investigate sequence-discriminative training of long short-term memory recurrent neural networks using the maximum mutual information criterion. We show that although recurrent neural networks already make use of the whole observation sequence and are able to incorporate more contextual information than feed forward networks, their performance can be improved with sequence-discriminative training. Experiments are performed on two publicly available handwriting recognition tasks containing English and French handwriting. On the English corpus, we obtain a relative improvement in WER of over 11% with maximum mutual information (MMI) training compared to cross-entropy training. On the French corpus, we observed that it is necessary to interpolate the MMI objective function with cross-entropy.
@InProceedings { voigtlaender2015:seq,
author= {Voigtlaender, Paul and Doetsch, Patrick and Wiesler, Simon and Schlüter, Ralf and Ney, Hermann},
title= {Sequence-Discriminative Training of Recurrent Neural Networks},
booktitle= {IEEE International Conference on Acoustics, Speech, and Signal Processing},
year= 2015,
pages= {2100-2104},
address= {Brisbane, Australia},
month= apr,
booktitlelink= {http://icassp2015.org/}
}
Multi-Layered Mapping and Navigation for Autonomous Micro Aerial Vehicles

Micro aerial vehicles, such as multirotors, are particularly well suited for the autonomous monitoring, inspection, and surveillance of buildings, e.g., for maintenance or disaster management. Key prerequisites for the fully autonomous operation of micro aerial vehicles are real-time obstacle detection and planning of collision-free trajectories. In this article, we propose a complete system with a multimodal sensor setup for omnidirectional obstacle perception consisting of a 3D laser scanner, two stereo camera pairs, and ultrasonic distance sensors. Detected obstacles are aggregated in egocentric local multiresolution grid maps. Local maps are efficiently merged in order to simultaneously build global maps of the environment and localize in these. For autonomous navigation, we generate trajectories in a multi-layered approach: from mission planning over global and local trajectory planning to reactive obstacle avoidance. We evaluate our approach and the involved components in simulation and with the real autonomous micro aerial vehicle. Finally, we present the results of a complete mission for autonomously mapping a building and its surroundings.
@article{droeschel15-jfr-mod,
author={D. Droeschel and M. Nieuwenhuisen and M. Beul and J. Stueckler and D. Holz and S. Behnke},
title={Multi-Layered Mapping and Navigation for Autonomous Micro Aerial Vehicles},
journal={Journal of Field Robotics},
year={2015},
note={published online},
}
Dense Continuous-Time Tracking and Mapping with Rolling Shutter RGB-D Cameras
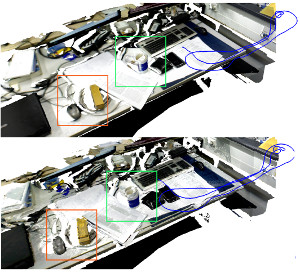
We propose a dense continuous-time tracking and mapping method for RGB-D cameras. We parametrize the camera trajectory using continuous B-splines and optimize the trajectory through dense, direct image alignment. Our method also directly models rolling shutter in both RGB and depth images within the optimization, which improves tracking and reconstruction quality for low-cost CMOS sensors. Using a continuous trajectory representation has a number of advantages over a discrete-time representation (e.g. camera poses at the frame interval). With splines, less variables need to be optimized than with a discrete represen- tation, since the trajectory can be represented with fewer control points than frames. Splines also naturally include smoothness constraints on derivatives of the trajectory estimate. Finally, the continuous trajectory representation allows to compensate for rolling shutter effects, since a pose estimate is available at any exposure time of an image. Our approach demonstrates superior quality in tracking and reconstruction compared to approaches with discrete-time or global shutter assumptions.
» Show BibTeX
@string{iccv="IEEE International Conference on Computer Vision (ICCV)"}
@inproceedings{kerl15iccv,
author = {C. Kerl and J. Stueckler and D. Cremers},
title = {Dense Continuous-Time Tracking and Mapping with Rolling Shutter {RGB-D} Cameras},
booktitle = iccv,
year = {2015},
address = {Santiago, Chile},
}
Motion Cooperation: Smooth Piece-Wise Rigid Scene Flow from RGB-D Images
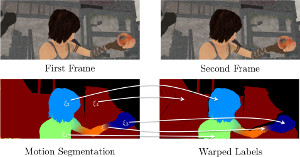
We propose a novel joint registration and segmentation approach to estimate scene flow from RGB-D images. In- stead of assuming the scene to be composed of a number of independent rigidly-moving parts, we use non-binary labels to capture non-rigid deformations at transitions between the rigid parts of the scene. Thus, the velocity of any point can be computed as a linear combination (interpolation) of the estimated rigid motions, which provides better results than traditional sharp piecewise segmentations. Within a variational framework, the smooth segments of the scene and their corresponding rigid velocities are alternately re- fined until convergence. A K-means-based segmentation is employed as an initialization, and the number of regions is subsequently adapted during the optimization process to capture any arbitrary number of independently moving ob- jects. We evaluate our approach with both synthetic and real RGB-D images that contain varied and large motions. The experiments show that our method estimates the scene flow more accurately than the most recent works in the field, and at the same time provides a meaningful segmentation of the scene based on 3D motion.
» Show BibTeX
@inproceedings{jaimez15_mocoop,
author= {M. Jaimez and M. Souiai and J. Stueckler and J. Gonzalez-Jimenez and D. Cremers},
title = {Motion Cooperation: Smooth Piece-Wise Rigid Scene Flow from RGB-D Images},
booktitle = {Proc. of the Int. Conference on 3D Vision (3DV)},
month = oct,
year = 2015,
}
Reconstructing Street-Scenes in Real-Time From a Driving Car

Most current approaches to street-scene 3D reconstruction from a driving car to date rely on 3D laser scanning or tedious offline computation from visual images. In this paper, we compare a real-time capable 3D reconstruction method using a stereo extension of large-scale di- rect SLAM (LSD-SLAM) with laser-based maps and traditional stereo reconstructions based on processing individual stereo frames. In our reconstructions, small-baseline comparison over several subsequent frames are fused with fixed-baseline disparity from the stereo camera setup. These results demonstrate that our direct SLAM technique provides an excellent compromise between speed and accuracy, generating visually pleasing and globally consistent semi- dense reconstructions of the environment in real-time on a single CPU.
@inproceedings{usenko15_3drecon_stereolsdslam,
author= {V. Usenko and J. Engel and J. Stueckler and D. Cremers},
title = {Reconstructing Street-Scenes in Real-Time From a Driving Car},
booktitle = {Proc. of the Int. Conference on 3D Vision (3DV)},
month = oct,
year = 2015,
}
Super-Resolution Keyframe Fusion for 3D Modeling with High-Quality Textures

We propose a novel fast and robust method for obtaining 3D models with high-quality appearance using commod- ity RGB-D sensors. Our method uses a direct keyframe- based SLAM frontend to consistently estimate the camera motion during the scan. The aligned images are fused into a volumetric truncated signed distance function rep- resentation, from which we extract a mesh. For obtaining a high-quality appearance model, we additionally deblur the low-resolution RGB-D frames using filtering techniques and fuse them into super-resolution keyframes. The meshes are textured from these sharp super-resolution keyframes employing a texture mapping approach. In experiments, we demonstrate that our method achieves superior quality in appearance compared to other state-of-the-art approaches.
@inproceedings{maier2015superresolution,
author= {R. Maier and J. Stueckler and D. Cremers},
title = {Super-Resolution Keyframe Fusion for 3D Modeling with High-Quality Textures},
booktitle = {International Conference on 3D Vision ({3DV})},
month = October,
year = 2015,
}
Large-Scale Direct SLAM with Stereo Cameras
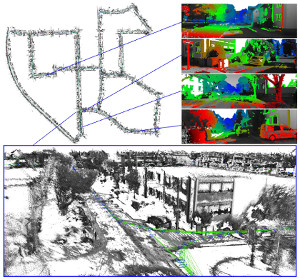
We propose a novel Large-Scale Direct SLAM algorithm for stereo cameras (Stereo LSD-SLAM) that runs in real-time at high frame rate on standard CPUs. In contrast to sparse interest-point based methods, our approach aligns images directly based on the photoconsistency of all high- contrast pixels, including corners, edges and high texture areas. It concurrently estimates the depth at these pixels from two types of stereo cues: Static stereo through the fixed-baseline stereo camera setup as well as temporal multi-view stereo exploiting the camera motion. By incorporating both disparity sources, our algorithm can even estimate depth of pixels that are under-constrained when only using fixed-baseline stereo. Using a fixed baseline, on the other hand, avoids scale-drift that typically occurs in pure monocular SLAM. We furthermore propose a robust approach to enforce illumination invariance, capable of handling aggressive brightness changes between frames – greatly improving the performance in realistic settings. In experiments, we demonstrate state-of-the-art results on stereo SLAM benchmarks such as Kitti or challenging datasets from the EuRoC Challenge 3 for micro aerial vehicles.
» Show BibTeX
@string{iros="International Conference on Intelligent Robots and Systems (IROS)"}
@inproceedings{engel2015_stereo_lsdslam,
author = {J. Engel and J. Stueckler and D. Cremers},
title = {Large-Scale Direct SLAM with Stereo Cameras},
booktitle = iros,
year = 2015,
month = sept,
}
Real-Time Object Detection, Localization and Verification for Fast Robotic Depalletizing
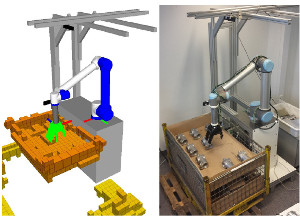
Depalletizing is a challenging task for manipulation robots. Key to successful application are not only robustness of the approach, but also achievable cycle times in order to keep up with the rest of the process. In this paper, we propose a system for depalletizing and a complete pipeline for detecting and localizing objects as well as verifying that the found object does not deviate from the known object model, e.g., if it is not the object to pick. In order to achieve high robustness (e.g., with respect to different lighting conditions) and generality with respect to the objects to pick, our approach is based on multi-resolution surfel models. All components (both software and hardware) allow operation at high frame rates and, thus, allow for low cycle times. In experiments, we demonstrate depalletizing of automotive and other prefabricated parts with both high reliability (w.r.t. success rates) and efficiency (w.r.t. low cycle times).
» Show BibTeX
@string{iros="International Conference on Intelligent Robots and Systems (IROS)"}
@inproceedings{holz2015_depalette,
author = {D. Holz and A. Topalidou-Kyniazopoulou and J. Stueckler and S. Behnke},
title = {Real-Time Object Detection, Localization and Verification for Fast Robotic Depalletizing},
booktitle = iros,
year = 2015,
}
SPENCER: A Socially Aware Service Robot for Passenger Guidance and Help in Busy Airports

We present an ample description of a socially compliant mobile robotic platform, which is developed in the EU-funded project SPENCER. The purpose of this robot is to assist, inform and guide passengers in large and busy airports. One particular aim is to bring travellers of connecting flights conveniently and efficiently from their arrival gate to the passport control. The uniqueness of the project stems from the strong demand of service robots for this application with a large potential impact for the aviation industry on one side, and on the other side from the scientific advancements in social robotics, brought forward and achieved in SPENCER. The main contributions of SPENCER are novel methods to perceive, learn, and model human social behavior and to use this knowledge to plan appropriate actions in real- time for mobile platforms. In this paper, we describe how the project advances the fields of detection and tracking of individuals and groups, recognition of human social relations and activities, normative human behavior learning, socially-aware task and motion planning, learning socially annotated maps, and conducting empir- ical experiments to assess socio-psychological effects of normative robot behaviors.
@article{triebel2015spencer,
title={SPENCER: a socially aware service robot for passenger guidance and help in busy airports},
author={Triebel, Rudolph and Arras, Kai and Alami, Rachid and Beyer, Lucas and Breuers, Stefan and Chatila, Raja and Chetouani, Mohamed and Cremers, Daniel and Evers, Vanessa and Fiore, Michelangelo and Hung, Hayley and Islas Ramírez, Omar A. and Joosse, Michiel and Khambhaita, Harmish and Kucner, Tomasz and Leibe, Bastian and Lilienthal, Achim J. and Linder, Timm and Lohse, Manja and Magnusson, Martin and Okal, Billy and Palmieri, Luigi and Rafi, Umer and Rooij, Marieke van and Zhang, Lu},
journal={Field and Service Robotics (FSR)
year={2015},
publisher={University of Toronto}
}
Previous Year (2014)
