
Publications
DynaMITe: Dynamic Query Bootstrapping for Multi-object Interactive Segmentation Transformer
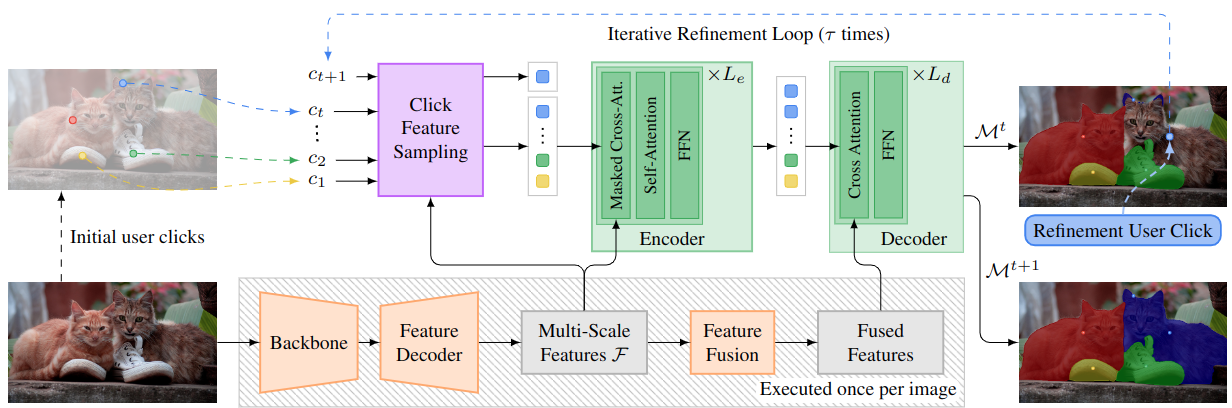
Most state-of-the-art instance segmentation methods rely on large amounts of pixel-precise ground-truth annotations for training, which are expensive to create. Interactive segmentation networks help generate such annotations based on an image and the corresponding user interactions such as clicks. Existing methods for this task can only process a single instance at a time and each user interaction requires a full forward pass through the entire deep network. We introduce a more efficient approach, called DynaMITe, in which we represent user interactions as spatio-temporal queries to a Transformer decoder with a potential to segment multiple object instances in a single iteration. Our architecture also alleviates any need to re-compute image features during refinement, and requires fewer interactions for segmenting multiple instances in a single image when compared to other methods. DynaMITe achieves state-of-the-art results on multiple existing interactive segmentation benchmarks, and also on the new multi-instance benchmark that we propose in this paper.
@article{RanaMahadevan23arxiv,
title={DynaMITe: Dynamic Query Bootstrapping for Multi-object Interactive Segmentation Transformer},
author={Rana, Amit and Mahadevan, Sabarinath and Alexander Hermans and Leibe, Bastian},
journal={arXiv preprint arXiv:2304.06668},
year={2023}
}
TarVis: A Unified Approach for Target-based Video Segmentation
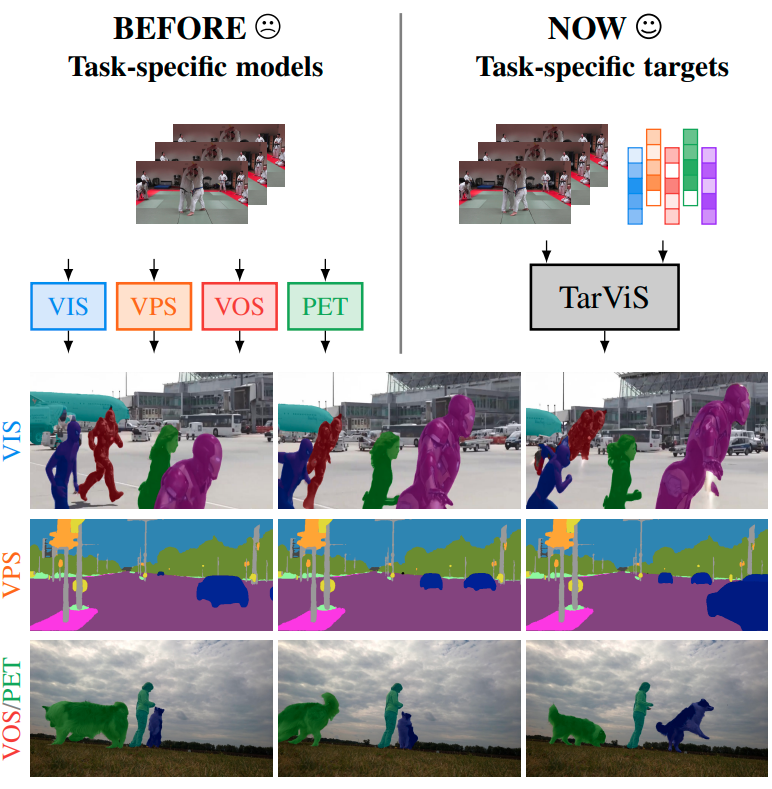
The general domain of video segmentation is currently fragmented into different tasks spanning multiple benchmarks. Despite rapid progress in the state-of-the-art, current methods are overwhelmingly task-specific and cannot conceptually generalize to other tasks. Inspired by recent approaches with multi-task capability, we propose TarViS: a novel, unified network architecture that can be applied to any task that requires segmenting a set of arbitrarily defined 'targets' in video. Our approach is flexible with respect to how tasks define these targets, since it models the latter as abstract 'queries' which are then used to predict pixel-precise target masks. A single TarViS model can be trained jointly on a collection of datasets spanning different tasks, and can hot-swap between tasks during inference without any task-specific retraining. To demonstrate its effectiveness, we apply TarViS to four different tasks, namely Video Instance Segmentation (VIS), Video Panoptic Segmentation (VPS), Video Object Segmentation (VOS) and Point Exemplar-guided Tracking (PET). Our unified, jointly trained model achieves state-of-the-art performance on 5/7 benchmarks spanning these four tasks, and competitive performance on the remaining two.
» Show BibTeX
@inproceedings{athar2023tarvis,
title={TarViS: A Unified Architecture for Target-based Video Segmentation},
author={Athar, Ali and Hermans, Alexander and Luiten, Jonathon and Ramanan, Deva and Leibe, Bastian},
booktitle={CVPR},
year={2023}
}
3D Segmentation of Humans in Point Clouds with Synthetic Data
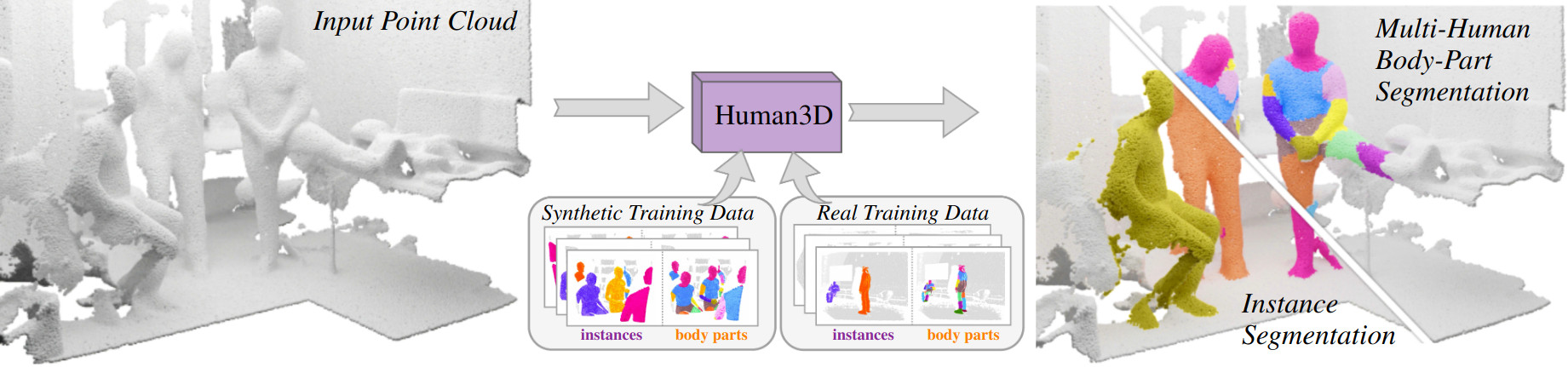
Segmenting humans in 3D indoor scenes has become increasingly important with the rise of human-centered robotics and AR/VR applications. In this direction, we explore the tasks of 3D human semantic-, instance- and multi-human body-part segmentation. Few works have attempted to directly segment humans in point clouds (or depth maps), which is largely due to the lack of training data on humans interacting with 3D scenes. We address this challenge and propose a framework for synthesizing virtual humans in realistic 3D scenes. Synthetic point cloud data is attractive since the domain gap between real and synthetic depth is small compared to images. Our analysis of different training schemes using a combination of synthetic and realistic data shows that synthetic data for pre-training improves performance in a wide variety of segmentation tasks and models. We further propose the first end-to-end model for 3D multi-human body-part segmentation, called Human3D, that performs all the above segmentation tasks in a unified manner. Remarkably, Human3D even outperforms previous task-specific state-of-the-art methods. Finally, we manually annotate humans in test scenes from EgoBody to compare the proposed training schemes and segmentation models.
@article{Takmaz23,
title = {{3D Segmentation of Humans in Point Clouds with Synthetic Data}},
author = {Takmaz, Ay\c{c}a and Schult, Jonas and Kaftan, Irem and Ak\c{c}ay, Mertcan
and Leibe, Bastian and Sumner, Robert and Engelmann, Francis and Tang, Siyu},
booktitle = {{International Conference on Computer Vision (ICCV)}},
year = {2023}
}
BURST: A Benchmark for Unifying Object Recognition, Segmentation and Tracking in Video

Multiple existing benchmarks involve tracking and segmenting objects in video e.g., Video Object Segmentation (VOS) and Multi-Object Tracking and Segmentation (MOTS), but there is little interaction between them due to the use of disparate benchmark datasets and metrics (e.g. J&F, mAP, sMOTSA). As a result, published works usually target a particular benchmark, and are not easily comparable to each another. We believe that the development of generalized methods that can tackle multiple tasks requires greater cohesion among these research sub-communities. In this paper, we aim to facilitate this by proposing BURST, a dataset which contains thousands of diverse videos with high-quality object masks, and an associated benchmark with six tasks involving object tracking and segmentation in video. All tasks are evaluated using the same data and comparable metrics, which enables researchers to consider them in unison, and hence, more effectively pool knowledge from different methods across different tasks. Additionally, we demonstrate several baselines for all tasks and show that approaches for one task can be applied to another with a quantifiable and explainable performance difference.
» Show BibTeX
@inproceedings{athar2023burst,
title={BURST: A Benchmark for Unifying Object Recognition, Segmentation and Tracking in Video},
author={Athar, Ali and Luiten, Jonathon and Voigtlaender, Paul and Khurana, Tarasha and Dave, Achal and Leibe, Bastian and Ramanan, Deva},
booktitle={WACV},
year={2023}
}
Learning 3D Human Pose Estimation from Dozens of Datasets using a Geometry-Aware Autoencoder to Bridge Between Skeleton Formats
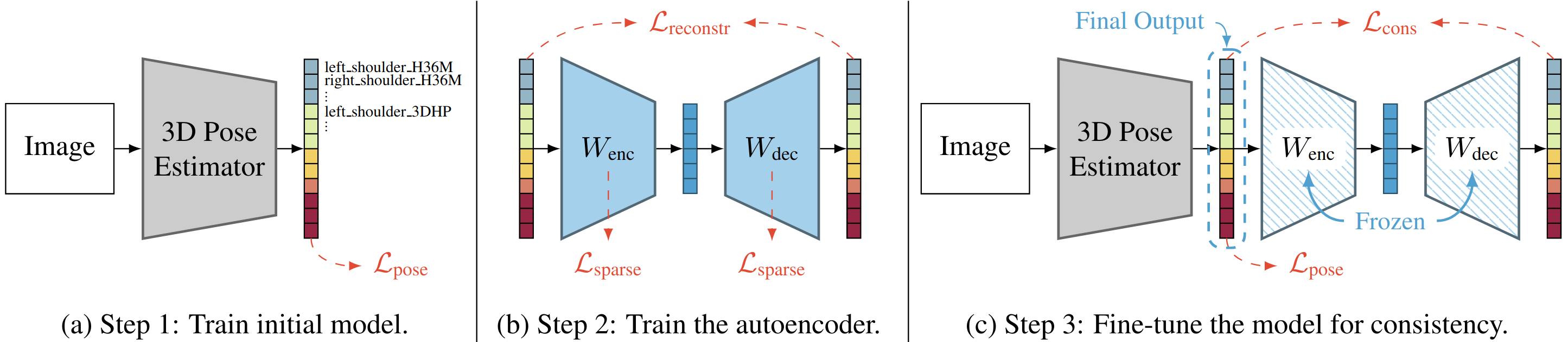
Deep learning-based 3D human pose estimation performs best when trained on large amounts of labeled data, making combined learning from many datasets an important research direction. One obstacle to this endeavor are the different skeleton formats provided by different datasets, i.e., they do not label the same set of anatomical landmarks. There is little prior research on how to best supervise one model with such discrepant labels. We show that simply using separate output heads for different skeletons results in inconsistent depth estimates and insufficient information sharing across skeletons. As a remedy, we propose a novel affine-combining autoencoder (ACAE) method to perform dimensionality reduction on the number of landmarks. The discovered latent 3D points capture the redundancy among skeletons, enabling enhanced information sharing when used for consistency regularization. Our approach scales to an extreme multi-dataset regime, where we use 28 3D human pose datasets to supervise one model, which outperforms prior work on a range of benchmarks, including the challenging 3D Poses in the Wild (3DPW) dataset. Our code and models are available for research purposes.
» Show BibTeX
@inproceedings{Sarandi23WACV,
author = {S\'ar\'andi, Istv\'an and Hermans, Alexander and Leibe, Bastian},
title = {Learning {3D} Human Pose Estimation from Dozens of Datasets using a Geometry-Aware Autoencoder to Bridge Between Skeleton Formats},
booktitle = {IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)},
year = {2023},
}
Mask3D for 3D Semantic Instance Segmentation

Modern 3D semantic instance segmentation approaches predominantly rely on specialized voting mechanisms followed by carefully designed geometric clustering techniques. Building on the successes of recent Transformer-based methods for object detection and image segmentation, we propose the first Transformer-based approach for 3D semantic instance segmentation. We show that we can leverage generic Transformer building blocks to directly predict instance masks from 3D point clouds. In our model called Mask3D each object instance is represented as an instance query. Using Transformer decoders, the instance queries are learned by iteratively attending to point cloud features at multiple scales. Combined with point features, the instance queries directly yield all instance masks in parallel. Mask3D has several advantages over current state-of-the-art approaches, since it neither relies on (1) voting schemes which require hand-selected geometric properties (such as centers) nor (2) geometric grouping mechanisms requiring manually-tuned hyper-parameters (e.g. radii) and (3) enables a loss that directly optimizes instance masks. Mask3D sets a new state-of-the-art on ScanNet test (+6.2 mAP), S3DIS 6-fold (+10.1 mAP), STPLS3D (+11.2 mAP) and ScanNet200 test (+12.4 mAP).
» Show BibTeX
@article{Schult23ICRA,
title = {{Mask3D for 3D Semantic Instance Segmentation}},
author = {Schult, Jonas and Engelmann, Francis and Hermans, Alexander and Litany, Or and Tang, Siyu and Leibe, Bastian},
booktitle = {{International Conference on Robotics and Automation (ICRA)}},
year = {2023}
}
Point2Vec for Self-Supervised Representation Learning on Point Clouds
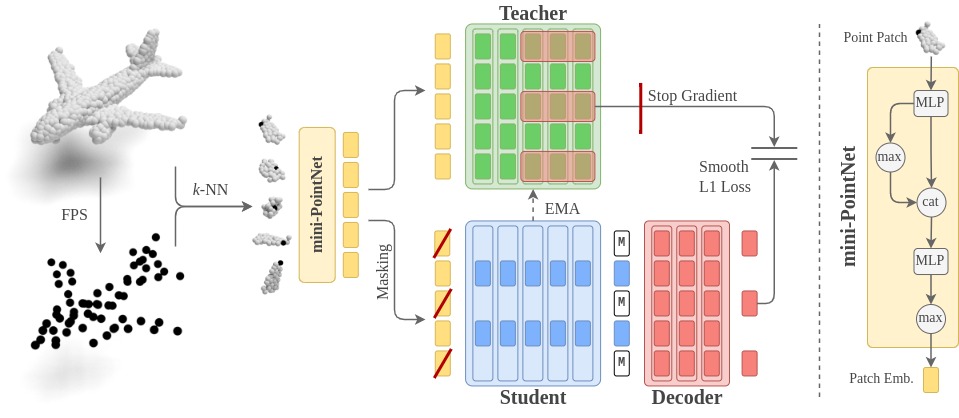
Recently, the self-supervised learning framework data2vec has shown inspiring performance for various modalities using a masked student-teacher approach. However, it remains open whether such a framework generalizes to the unique challenges of 3D point clouds.To answer this question, we extend data2vec to the point cloud domain and report encouraging results on several downstream tasks. In an in-depth analysis, we discover that the leakage of positional information reveals the overall object shape to the student even under heavy masking and thus hampers data2vec to learn strong representations for point clouds. We address this 3D-specific shortcoming by proposing point2vec, which unleashes the full potential of data2vec-like pre-training on point clouds. Our experiments show that point2vec outperforms other self-supervised methods on shape classification and few-shot learning on ModelNet40 and ScanObjectNN, while achieving competitive results on part segmentation on ShapeNetParts. These results suggest that the learned representations are strong and transferable, highlighting point2vec as a promising direction for self-supervised learning of point cloud representations.
@InProceedings{knaebel2023point2vec,
title = {Point2Vec for Self-Supervised Representation Learning on Point Clouds},
author = {Knaebel, Karim and Schult, Jonas and Hermans, Alexander and Leibe, Bastian},
journal = {German Conference on Pattern Recognition (GCPR)},
year = {2023}
}
Clicks as Queries: Interactive Transformer for Multi-instance Segmentation
Transformers have percolated into a multitude of computer vision domains including dense prediction tasks such as instance segmentation and have demonstrated strong performances. Existing transformer based segmentation approaches such as Mask2Former generate pixel-precise object masks automatically given an input image. While these methods are capable of generating high quality masks in general, they have an inherent class bias and are unable to incorporate user inputs to either segment out-of-distribution classes or to correct bad predictions. Hence, we introduce a novel module called Interactive Transformer that enables transformers to predict and refine objects based on user interactions. Subsequently, we use our Interactive Transformer to develop an interactive segmentation network that can generate mask predictions based on user clicks and thereby widen the transformer application domains within computer vision. In addition, the Interactive Transformer can make such interactive segmentation tasks more efficient by (i) imparting the ability to perform multi-instances segmentation, (ii) alleviating the need to re-compute image-level backbone features as done in existing interactive segmentation networks, and (iii) reducing the required number of user interactions by modeling a common background representation. Our transformer-based architecture outperforms the state-of-the-art interactive segmentation networks on multiple benchmark datasets.
@inproceedings{RanaMahadevan23cvprw,
title={Clicks as Queries: Interactive Transformer for Multi-instance Segmentation},
author={Rana, Amit and Mahadevan, Sabarinath and Alexander Hermans and Leibe, Bastian},
booktitle={CVPRW},
year={2023}
}
UGainS: Uncertainty Guided Anomaly Segmentation

A single unexpected object on the road can cause an accident or may lead to injuries. To prevent this, we need a reliable mechanism for finding anomalous objects on the road. This task, called anomaly segmentation, can be a stepping stone to safe and reliable autonomous driving. Current approaches tackle anomaly segmentation by assigning an anomaly score to each pixel and by grouping anomalous regions using simple heuristics. However, pixel grouping is a limiting factor when it comes to evaluating the segmentation performance of individual anomalous objects. To address the issue of grouping multiple anomaly instances into one, we propose an approach that produces accurate anomaly instance masks. Our approach centers on an out-of-distribution segmentation model for identifying uncertain regions and a strong generalist segmentation model for anomaly instances segmentation. We investigate ways to use uncertain regions to guide such a segmentation model to perform segmentation of anomalous instances. By incorporating strong object priors from a generalist model we additionally improve the per-pixel anomaly segmentation performance. Our approach outperforms current pixel-level anomaly segmentation methods, achieving an AP of 80.08% and 88.98% on the Fishyscapes Lost and Found and the RoadAnomaly validation sets respectively.
```
@inproceedings{nekrasov2023ugains,
title = {{UGainS: Uncertainty Guided Anomaly Instance Segmentation}},
author = {Nekrasov, Alexey and Hermans, Alexander and Kuhnert, Lars and Leibe, Bastian},
booktitle = {GCPR},
year = {2023}
}
```
Previous Year (2022)
