
Publications
4D-StOP: Panoptic Segmentation of 4D LiDAR using Spatio-temporal Object Proposal Generation and Aggregation
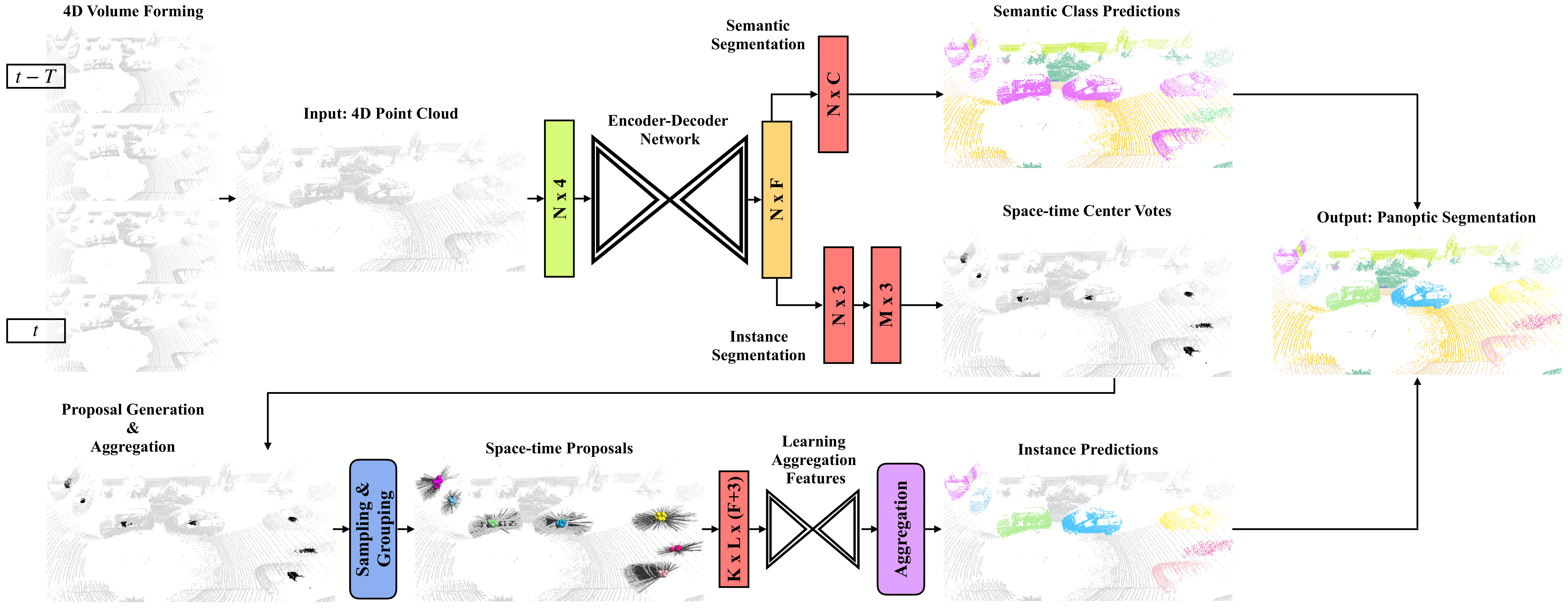
In this work, we present a new paradigm, called 4D-StOP, to tackle the task of 4D Panoptic LiDAR Segmentation. 4D-StOP first generates spatio-temporal proposals using voting-based center predictions, where each point in the 4D volume votes for a corresponding center. These tracklet proposals are further aggregated using learned geometric features. The tracklet aggregation method effectively generates a video-level 4D scene representation over the entire space-time volume. This is in contrast to existing end-to-end trainable state-of-the-art approaches which use spatio-temporal embeddings that are represented by Gaussian probability distributions. Our voting-based tracklet generation method followed by geometric feature-based aggregation generates significantly improved panoptic LiDAR segmentation quality when compared to modeling the entire 4D volume using Gaussian probability distributions. 4D-StOP achieves a new state-of-the-art when applied to the SemanticKITTI test dataset with a score of 63.9 LSTQ, which is a large (+7%) improvement compared to current best-performing end-to-end trainable methods. The code and pre-trained models are available at:https://github.com/LarsKreuzberg/4D-StOP
HODOR: High-level Object Descriptors for Object Re-segmentation in Video Learned from Static Images
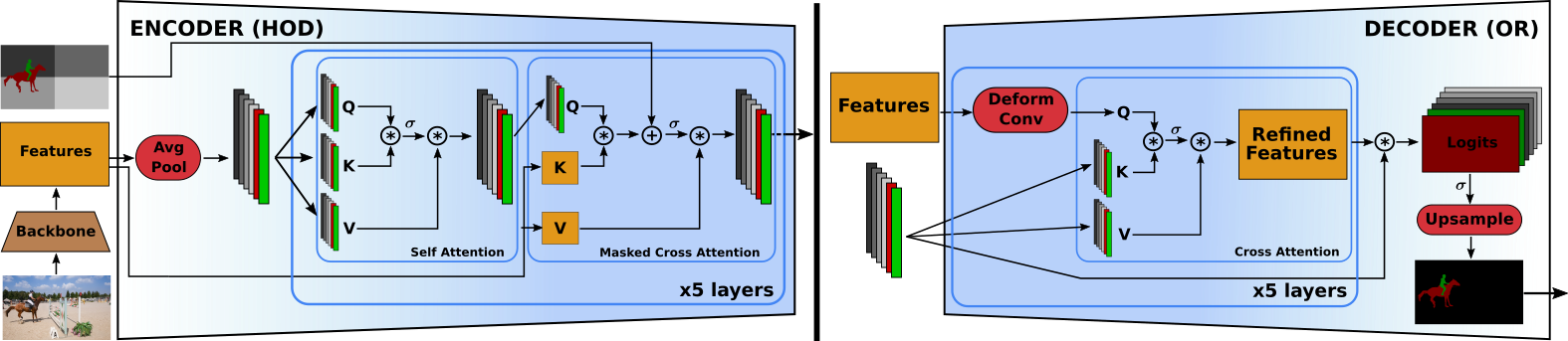
Existing state-of-the-art methods for Video Object Segmentation (VOS) learn low-level pixel-to-pixel correspondences between frames to propagate object masks across video. This requires a large amount of densely annotated video data, which is costly to annotate, and largely redundant since frames within a video are highly correlated. In light of this, we propose HODOR: a novel method that tackles VOS by effectively leveraging annotated static images for understanding object appearance and scene context. We encode object instances and scene information from an image frame into robust high-level descriptors which can then be used to re-segment those objects in different frames. As a result, HODOR achieves state-of-the-art performance on the DAVIS and YouTube-VOS benchmarks compared to existing methods trained without video annotations. Without any architectural modification, HODOR can also learn from video context around single annotated video frames by utilizing cyclic consistency, whereas other methods rely on dense, temporally consistent annotations.
@article{Athar22CVPR,
title = {{HODOR: High-level Object Descriptors for Object Re-segmentation in Video Learned from Static Images}},
author = {Athar, Ali and Luiten, Jonathon and Hermans, Alexander and Ramanan, Deva and Leibe, Bastian},
journal = {{IEEE Conference on Computer Vision and Pattern Recognition (CVPR'22)}},
year = {2022}
}
Opening up Open World Tracking

Tracking and detecting any object, including ones never-seen-before during model training, is a crucial but elusive capability of autonomous systems. An autonomous agent that is blind to never-seen-before objects poses a safety hazard when operating in the real world and yet this is how almost all current systems work. One of the main obstacles towards advancing tracking any object is that this task is notoriously difficult to evaluate. A benchmark that would allow us to perform an apples-to-apples comparison of existing efforts is a crucial first step towards advancing this important research field. This paper addresses this evaluation deficit and lays out the landscape and evaluation methodology for detecting and tracking both known and unknown objects in the open-world setting. We propose a new benchmark, TAO-OW: Tracking Any Object in an Open World}, analyze existing efforts in multi-object tracking, and construct a baseline for this task while highlighting future challenges. We hope to open a new front in multi-object tracking research that will hopefully bring us a step closer to intelligent systems that can operate safely in the real world.
@inproceedings{liu2022opening,
title={Opening up Open-World Tracking},
author={Liu, Yang and Zulfikar, Idil Esen and Luiten, Jonathon and Dave, Achal and Ramanan, Deva and Leibe, Bastian and O{\v{s}}ep, Aljo{\v{s}}a and Leal-Taix{\'e}, Laura},
journal={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2022}
}
M2F3D: Mask2Former for 3D Instance Segmentation
In this work, we show that the top performing Mask2Former approach for image-based segmentation tasks works surprisingly well when adapted to the 3D scene understanding domain. Current 3D semantic instance segmentation methods rely largely on predicting centers followed by clustering approaches and little progress has been made in applying transformer-based approaches to this task. We show that with small modifications to the Mask2Former approach for 2D, we can create a 3D instance segmentation approach, without the need for highly 3D specific components or carefully hand-engineered hyperparameters. Initial experiments with our M2F3D model on the ScanNet benchmark are very promising and sets a new state-of-the-art on ScanNet test (+0.4 mAP50).
Please see our extended work Mask3D: Mask Transformer for 3D Instance Segmentation accepted at ICRA 2023.
Global Hierarchical Attention for 3D Point Cloud Analysis
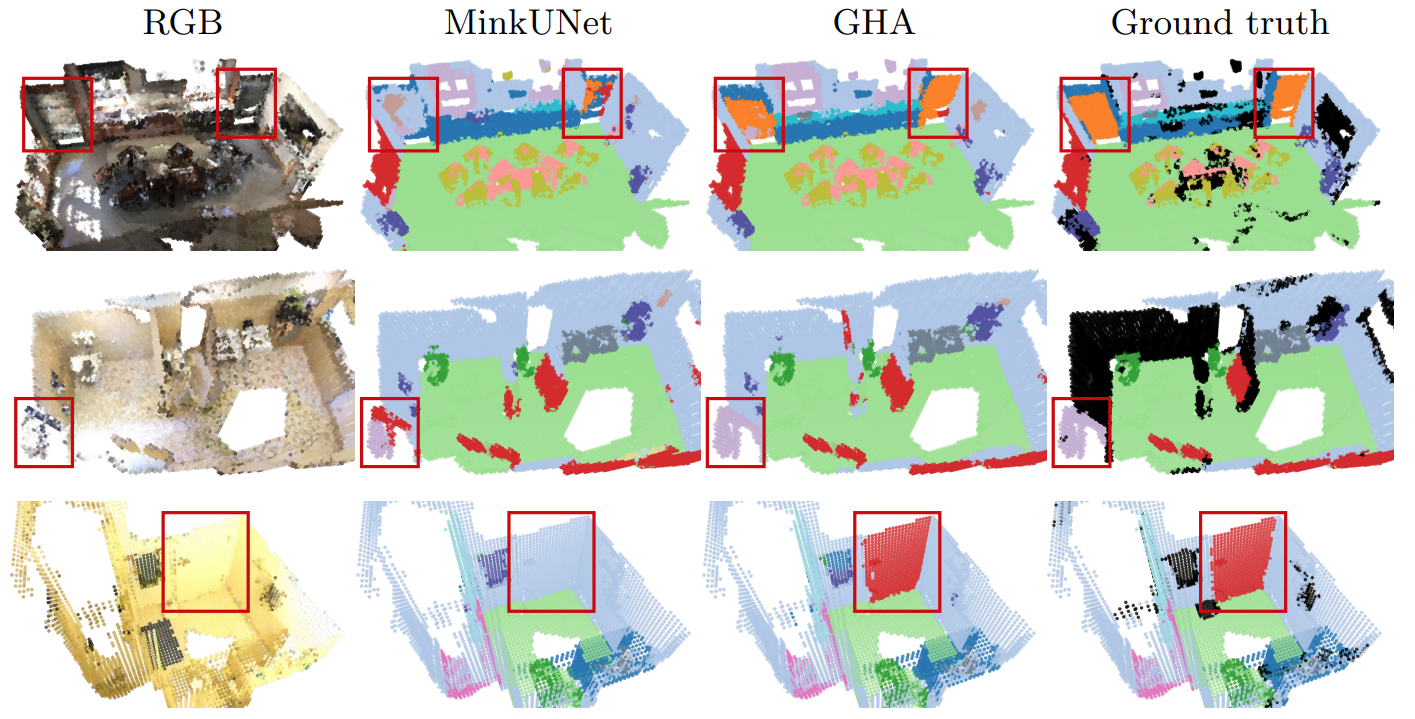
We propose a new attention mechanism, called Global Hierarchical Attention (GHA), for 3D point cloud analysis. GHA approximates the regular global dot-product attention via a series of coarsening and interpolation operations over multiple hierarchy levels. The advantage of GHA is two-fold. First, it has linear complexity with respect to the number of points, enabling the processing of large point clouds. Second, GHA inherently possesses the inductive bias to focus on spatially close points, while retaining the global connectivity among all points. Combined with a feedforward network, GHA can be inserted into many existing network architectures. We experiment with multiple baseline networks and show that adding GHA consistently improves performance across different tasks and datasets. For the task of semantic segmentation, GHA gives a +1.7% mIoU increase to the MinkowskiEngine baseline on ScanNet. For the 3D object detection task, GHA improves the CenterPoint baseline by +0.5% mAP on the nuScenes dataset, and the 3DETR baseline by +2.1% mAP25 and +1.5% mAP50 on ScanNet.
Pedestrian-Robot Interactions on Autonomous Crowd Navigation: Reactive Control Methods and Evaluation Metrics

Autonomous navigation in highly populated areas remains a challenging task for robots because of the difficulty in guaranteeing safe interactions with pedestrians in unstructured situations. In this work, we present a crowd navigation control framework that delivers continuous obstacle avoidance and post-contact control evaluated on an autonomous personal mobility vehicle. We propose evaluation metrics for accounting efficiency, controller response and crowd interactions in natural crowds. We report the results of over 110 trials in different crowd types: sparse, flows, and mixed traffic, with low- (< 0.15 ppsm), mid- (< 0.65 ppsm), and high- (< 1 ppsm) pedestrian densities. We present comparative results between two low-level obstacle avoidance methods and a baseline of shared control. Results show a 10% drop in relative time to goal on the highest density tests, and no other efficiency metric decrease. Moreover, autonomous navigation showed to be comparable to shared-control navigation with a lower relative jerk and significantly higher fluency in commands indicating high compatibility with the crowd. We conclude that the reactive controller fulfills a necessary task of fast and continuous adaptation to crowd navigation, and it should be coupled with high-level planners for environmental and situational awareness.
Differentiable Soft-Masked Attention
Transformers have become prevalent in computer vision due to their performance and flexibility in modelling complex operations. Of particular significance is the ‘cross-attention’ operation, which allows a vector representation (e.g. of an object in an image) to be learned by ‘attending’ to an arbitrarily sized set of input features. Recently, ‘Masked Attention’ was proposed in which a given object representation only attends to those image pixel features for which the segmentation mask of that object is active. This specialization of attention proved beneficial for various image and video segmentation tasks. In this paper, we propose another specialization of attention which enables attending over ‘soft-masks’ (those with continuous mask probabilities instead of binary values), and is also differentiable through these mask probabilities, thus allowing the mask used for attention to be learned within the network without requiring direct loss supervision. This can be useful for several applications. Specifically, we employ our ‘Differentiable Soft-Masked Attention’ for the task of Weakly Supervised Video Object Segmentation (VOS), where we develop a transformer-based network for VOS which only requires a single annotated image frame for training, but can also benefit from cycle consistency training on a video with just one annotated frame. Although there is no loss for masks in unlabeled frames, the network is still able to segment objects in those frames due to our novel attention formulation.
2D vs. 3D LiDAR-based Person Detection on Mobile Robots
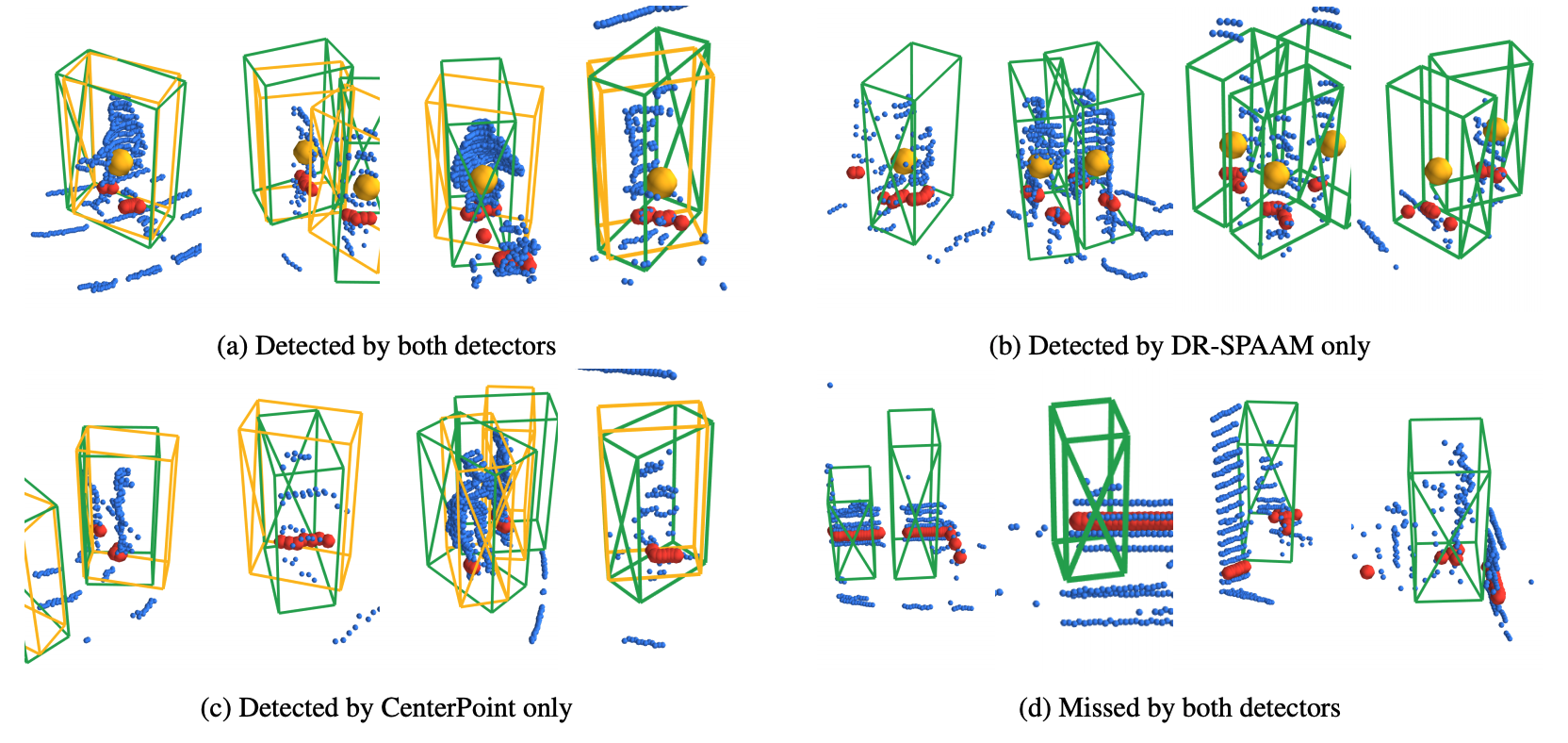
Person detection is a crucial task for mobile robots navigating in human-populated environments. LiDAR sensors are promising for this task, thanks to their accurate depth measurements and large field of view. Two types of LiDAR sensors exist: the 2D LiDAR sensors, which scan a single plane, and the 3D LiDAR sensors, which scan multiple planes, thus forming a volume. How do they compare for the task of person detection? To answer this, we conduct a series of experiments, using the public, large-scale JackRabbot dataset and the state-of-the-art 2D and 3D LiDAR-based person detectors (DR-SPAAM and CenterPoint respectively). Our experiments include multiple aspects, ranging from the basic performance and speed comparison, to more detailed analysis on localization accuracy and robustness against distance and scene clutter. The insights from these experiments highlight the strengths and weaknesses of 2D and 3D LiDAR sensors as sources for person detection, and are especially valuable for designing mobile robots that will operate in close proximity to surrounding humans (e.g. service or social robot).
Previous Year (2021)
