
Publications
Incremental Object Discovery in Time-Varying Image Collections
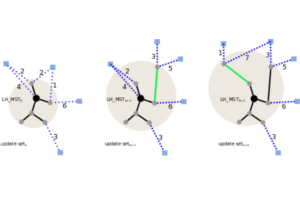
In this paper, we address the problem of object discovery in time-varying, large-scale image collections. A core part of our approach is a novel Limited Horizon Minimum Spanning Tree (LH-MST) structure that closely approximates the Minimum Spanning Tree at a small fraction of the latter’s computational cost. Our proposed tree structure can be created in a local neighborhood of the matching graph during image retrieval and can be efficiently updated whenever the image database is extended. We show how the LH-MST can be used within both single-link hierarchical agglomerative clustering and the Iconoid Shift framework for object discovery in image collections, resulting in significant efficiency gains and making both approaches capable of incremental clustering with online updates. We evaluate our approach on a dataset of 500k images from the city of Paris and compare its results to the batch version of both clustering algorithms.
PatchIt: Self-supervised Network Weight Initialization for Fine-grained Recognition
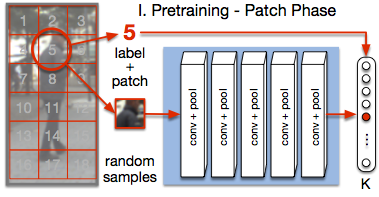
ConvNet training is highly sensitive to initialization of the weights. A widespread approach is to initialize the network with weights trained for a different task, an auxiliary task. The ImageNet-based ILSVRC classification task is a very popular choice for this, as it has shown to produce powerful feature representations applicable to a wide variety of tasks. However, this creates a significant entry barrier to exploring non-standard architectures. In this paper, we propose a self-supervised pretraining, the PatchTask, to obtain weight initializations for fine-grained recognition problems, such as person attribute recognition, pose estimation, or action recognition. Our pretraining allows us to leverage additional unlabeled data from the same source, which is often readily available, such as detection bounding boxes. We experimentally show that our method outperforms a standard random initialization by a considerable margin and closely matches the ImageNet-based initialization.
@InProceedings{Sudowe16BMVC,
author = {Patrick Sudowe and Bastian Leibe},
title = {{PatchIt: Self-Supervised Network Weight Initialization for Fine-grained Recognition}},
booktitle = BMVC,
year = {2016}
}
Unsupervised Learning of Shape-Motion Patterns for Objects in Urban Street Scenes
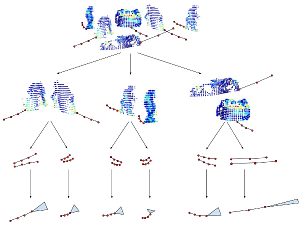
Tracking in urban street scenes is predominantly based on pretrained object-specific detectors and Kalman filter based tracking. More recently, methods have been proposed that track objects by modelling their shape, as well as ones that predict the motion of ob- jects using learned trajectory models. In this paper, we combine these ideas and propose shape-motion patterns (SMPs) that incorporate shape as well as motion to model a vari- ety of objects in an unsupervised way. By using shape, our method can learn trajectory models that distinguish object categories with distinct behaviour. We develop methods to classify objects into SMPs and to predict future motion. In experiments, we analyze our learned categorization and demonstrate superior performance of our motion predictions compared to a Kalman filter and a learned pure trajectory model. We also demonstrate how SMPs can indicate potentially harmful situations in traffic scenarios.
» Show BibTeX
@inproceedings{klostermann2016_smps,
title = {Unsupervised Learning of Shape-Motion Patterns for Objects in Urban Street Scenes},
author = {Dirk Klostermann and Aljosa Osep and J\"org St\"uckler and Bastian Leibe},
booktitle = {Proc. of the British Machine Vision Conference (BMVC)},
year = {2016}, note = {to appear}
}
Scene Flow Propagation for Semantic Mapping and Object Discovery in Dynamic Street Scenes

Scene understanding is an important prerequisite for vehicles and robots that operate autonomously in dynamic urban street scenes. For navigation and high-level behavior planning, the robots not only require a persistent 3D model of the static surroundings - equally important, they need to perceive and keep track of dynamic objects. In this paper, we propose a method that incrementally fuses stereo frame observations into temporally consistent semantic 3D maps. In contrast to previous work, our approach uses scene flow to propagate dynamic objects within the map. Our method provides a persistent 3D occupancy as well as semantic belief on static as well as moving objects. This allows for advanced reasoning on objects despite noisy single-frame observations and occlusions. We develop a novel approach to discover object instances based on the temporally consistent shape, appearance, motion, and semantic cues in our maps. We evaluate our approaches to dynamic semantic mapping and object discovery on the popular KITTI benchmark and demonstrate improved results compared to single-frame methods.
» Show BibTeX
@inproceedings{kochanov2016_sceneflowprop,
title = {Scene Flow Propagation for Semantic Mapping and Object Discovery in Dynamic Street Scenes},
author = {Deyvid Kochanov and Aljosa Osep and J\"org St\"uckler and Bastian Leibe},
booktitle = {Proc. of the IEEE Int. Conf. on Intelligent Robots and Systems (IROS)}, year = {2016},
note = {to appear}
}
Joint Object Pose Estimation and Shape Reconstruction in Urban Street Scenes Using 3D Shape Priors

Estimating the pose and 3D shape of a large variety of instances within an object class from stereo images is a challenging problem, especially in realistic conditions such as urban street scenes. We propose a novel approach for using compact shape manifolds of the shape within an object class for object segmentation, pose and shape estimation. Our method first detects objects and estimates their pose coarsely in the stereo images using a state-of-the-art 3D object detection method. An energy minimization method then aligns shape and pose concurrently with the stereo reconstruction of the object. In experiments, we evaluate our approach for detection, pose and shape estimation of cars in real stereo images of urban street scenes. We demonstrate that our shape manifold alignment method yields improved results over the initial stereo reconstruction and object detection method in depth and pose accuracy.
» Show BibTeX
@inproceedings{EngelmannGCPR16_shapepriors,
title = {Joint Object Pose Estimation and Shape Reconstruction in Urban Street Scenes Using {3D} Shape Priors},
author = {Francis Engelmann and J\"org St\"uckler and Bastian Leibe},
booktitle = {Proc. of the German Conference on Pattern Recognition (GCPR)},
year = {2016}}
Multi-Scale Object Candidates for Generic Object Tracking in Street Scenes

Most vision based systems for object tracking in urban environments focus on a limited number of important object categories such as cars or pedestrians, for which powerful detectors are available. However, practical driving scenarios contain many additional objects of interest, for which suitable detectors either do not yet exist or would be cumbersome to obtain. In this paper we propose a more general tracking approach which does not follow the often used tracking-by- detection principle. Instead, we investigate how far we can get by tracking unknown, generic objects in challenging street scenes. As such, we do not restrict ourselves to only tracking the most common categories, but are able to handle a large variety of static and moving objects. We evaluate our approach on the KITTI dataset and show competitive results for the annotated classes, even though we are not restricted to them.
@inproceedings{Osep16ICRA,
title={Multi-Scale Object Candidates for Generic Object Tracking in Street
Scenes},
author={O\v{s}ep, Aljo\v{s}a and Hermans, Alexander and Engelmann, Francis and Klostermann, Dirk and and Mathias, Markus and Leibe, Bastian},
booktitle={ICRA},
year={2016}
}
CPA-SLAM: Consistent Plane-Model Alignment for Direct RGB-D SLAM
Planes are predominant features of man-made environments which have been exploited in many mapping approaches. In this paper, we propose a real-time capable RGB-D SLAM system that consistently integrates frame-to-keyframe and frame-to-plane alignment. Our method models the environment with a global plane model and – besides direct image alignment – it uses the planes for tracking and global graph optimization. This way, our method makes use of the dense image information available in keyframes for accurate short-term tracking. At the same time it uses a global model to reduce drift. Both components are integrated consistently in an expectation-maximization framework. In experiments, we demonstrate the benefits our approach and its state-of-the-art accuracy on challenging benchmarks.
@InProceedings{lingni16icra,
author = "L. Ma and C. Kerl and J. Stueckler and D. Cremers",
title = "CPA-SLAM: Consistent Plane-Model Alignment for Direct RGB-D SLAM",
booktitle = "Int. Conf. on Robotics and Automation",
year = "2016",
month = "May",
}
Direct Visual-Inertial Odometry with Stereo Cameras
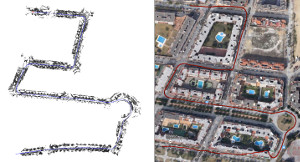
We propose a novel direct visual-inertial odometry method for stereo cameras. Camera pose, velocity and IMU biases are simultaneously estimated by minimizing a combined photometric and inertial energy functional. This allows us to exploit the complementary nature of vision and inertial data. At the same time, and in contrast to all existing visual-inertial methods, our approach is fully direct: geometry is estimated in the form of semi-dense depth maps instead of manually designed sparse keypoints. Depth information is obtained both from static stereo – relating the fixed-baseline images of the stereo camera – and temporal stereo – relating images from the same camera, taken at different points in time. We show that our method outperforms not only vision-only or loosely coupled approaches, but also can achieve more accurate results than state-of-the-art keypoint-based methods on different datasets, including rapid motion and significant illumination changes. In addition, our method provides high-fidelity semi-dense, metric reconstructions of the environment, and runs in real-time on a CPU.
» Show BibTeX
@InProceedings{usenko16icra,
title = "Direct Visual-Inertial Odometry with Stereo Cameras",
author = "V. Usenko and J. Engel and J. Stueckler and D. Cremers",
booktitle = {Int. Conf. on Robotics and Automation},
year = "2016",
}
Mobile Manipulation, Tool Use, and Intuitive Interaction for Cognitive Service Robot Cosero

Cognitive service robots that shall assist persons in need of performing their activities of daily living have recently received much attention in robotics research. Such robots require a vast set of control and perception capabilities to provide useful assistance through mobile manipulation and human–robot interaction. In this article, we present hardware design, perception, and control methods for our cognitive service robot Cosero. We complement autonomous capabilities with handheld teleoperation interfaces on three levels of autonomy. The robot demonstrated various advanced skills, including the use of tools. With our robot, we participated in the annual international RoboCup@Home competitions, winning them three times in a row.
» Show BibTeX
@ARTICLE{stueckler2016_cosero,
AUTHOR={St\"uckler, J\"org and Schwarz, Max and Behnke, Sven},
TITLE={Mobile Manipulation, Tool Use, and Intuitive Interaction for Cognitive Service Robot Cosero},
JOURNAL={Frontiers in Robotics and AI},
VOLUME={3},
PAGES={58},
YEAR={2016},
URL={http://journal.frontiersin.org/article/10.3389/frobt.2016.00058},
DOI={10.3389/frobt.2016.00058},
}
The STRANDS Project: Long-Term Autonomy in Everyday Environments

Thanks to the efforts of our community, autonomous robots are becoming capable of ever more complex and impressive feats. There is also an increasing demand for, perhaps even an expectation of, autonomous capabilities from end-users. However, much research into autonomous robots rarely makes it past the stage of a demonstration or experimental system in a controlled environment. If we don't confront the challenges presented by the complexity and dynamics of real end-user environments, we run the risk of our research becoming irrelevant or ignored by the industries who will ultimately drive its uptake. In the STRANDS project we are tackling this challenge head-on. We are creating novel autonomous systems, integrating state-of-the-art research in artificial intelligence and robotics into robust mobile service robots, and deploying these systems for long-term installations in security and care environments. To date, over four deployments, our robots have been operational for a combined duration of 2545 hours (or a little over 106 days), covering 116km while autonomously performing end-user defined tasks. In this article we present an overview of the motivation and approach of the STRANDS project, describe the technology we use to enable long, robust autonomous runs in challenging environments, and describe how our robots are able to use these long runs to improve their own performance through various forms of learning.
Semantic Segmentation of Modular Furniture

This paper proposes an approach for the semantic seg- mentation and structural parsing of modular furniture items, such as cabinets, wardrobes, and bookshelves, into so called interaction elements. Such a segmentation into functional units is challenging not only due to the visual similarity of the different elements but also because of their often uniformly colored and low-texture appearance. Our method addresses these challenges by merging structural and appearance likelihoods of each element and jointly op- timizing over shape, relative location, and class labels us- ing Markov Chain Monte Carlo (MCMC) sampling. We propose a novel concept called rectangle coverings which provides a tight bound on the number of structural elements and hence narrows down the search space. We evaluate our approach’s performance on a novel dataset of furniture items and demonstrate its applicability in practice.
@inproceedings{badamiWACV17,
title={Semantic Segmentation of Modular Furniture},
author={Pohlen, Tobias and Badami, Ishrat and Mathias, Markus and Leibe, Bastian},
booktitle={WACV},
year={2016}
}
Superpixels: An Evaluation of the State-of-the-Art
Superpixels group perceptually similar pixels to create visually meaningful entities while heavily reducing the number of primitives. As of these properties, superpixel algorithms have received much attention since their naming in 2003. By today, publicly available and well-understood superpixel algorithms have turned into standard tools in low-level vision. As such, and due to their quick adoption in a wide range of applications, appropriate benchmarks are crucial for algorithm selection and comparison. Until now, the rapidly growing number of algorithms as well as varying experimental setups hindered the development of a unifying benchmark. We present a comprehensive evaluation of 28 state-of-the-art superpixel algorithms utilizing a benchmark focussing on fair comparison and designed to provide new and relevant insights. To this end, we explicitly discuss parameter optimization and the importance of strictly enforcing connectivity. Furthermore, by extending well-known metrics, we are able to summarize algorithm performance independent of the number of generated superpixels, thereby overcoming a major limitation of available benchmarks. Furthermore, we discuss runtime, robustness against noise, blur and affine transformations, implementation details as well as aspects of visual quality. Finally, we present an overall ranking of superpixel algorithms which redefines the state-of-the-art and enables researchers to easily select appropriate algorithms and the corresponding implementations which themselves are made publicly available as part of our benchmark at davidstutz.de/projects/superpixel-benchmark/.
@article{Stutz2016Arxiv,
title = {{Superpixels: An Evaluation of the State-of-the-Art}},
author = {David Stutz and Alexander Hermans and Bastian Leibe},
journal = {arXiv preprint arXiv:1612.01601},
year = {2016}
}
An Efficient Convolutional Network for Human Pose Estimation
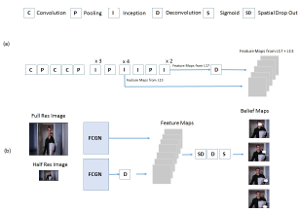
In recent years, human pose estimation has greatly benefited from deep learning and huge gains in performance have been achieved. The trend to maximise the accuracy on benchmarks, however, resulted in computationally expensive deep network architectures that require expensive hardware and pre-training on large datasets. This makes it difficult to compare different methods and to reproduce existing results. We therefore propose in this work an efficient deep network architecture that can be efficiently trained on mid-range GPUs without the need of any pre-training. Despite of the low computational requirements of our network, it is on par with much more complex models on popular benchmarks for human pose estimation.
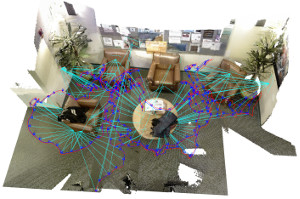
On Multi-Modal People Tracking from Mobile Platforms in Very Crowded and Dynamic Environments

Tracking people is a key technology for robots and intelligent systems in human environments. Many person detectors, filtering methods and data association algorithms for people tracking have been proposed in the past 15+ years in both the robotics and computer vision communities, achieving decent tracking performances from static and mobile platforms in real-world scenarios. However, little effort has been made to compare these methods, analyze their performance using different sensory modalities and study their impact on different performance metrics. In this paper, we propose a fully integrated real-time multi-modal laser/RGB-D people tracking framework for moving platforms in environments like a busy airport terminal. We conduct experiments on two challenging new datasets collected from a first-person perspective, one of them containing very dense crowds of people with up to 30 individuals within close range at the same time. We consider four different, recently proposed tracking methods and study their impact on seven different performance metrics, in both single and multi-modal settings. We extensively discuss our findings, which indicate that more complex data association methods may not always be the better choice, and derive possible future research directions.
» Show BibTeX
@incollection{linder16multi,
title={On Multi-Modal People Tracking from Mobile Platforms in Very Crowded and Dynamic Environments},
author={Linder, Timm and Breuers, Stefan and Leibe, Bastian and Arras, Kai Oliver},
booktitle={ICRA},
year={2016},
}
Exploring Bounding Box Context for Multi-Object Tracker Fusion
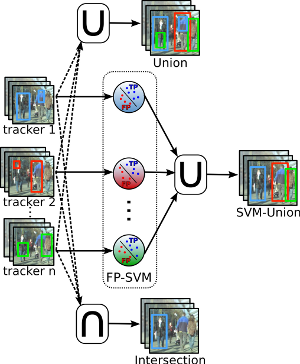
Many multi-object-tracking (MOT) techniques have been developed over the past years. The most successful ones are based on the classical tracking-by-detection approach. The different methods rely on different kinds of data association, use motion and appearance models, or add optimization terms for occlusion and exclusion. Still, errors occur for all those methods and a consistent evaluation has just started. In this paper we analyze three current state-of-the-art MOT trackers and show that there is still room for improvement. To that end, we train a classifier on the trackers' output bounding boxes in order to prune false positives. Furthermore, the different approaches have different strengths resulting in a reduced false negative rate when combined. We perform an extensive evaluation over ten common evaluation sequences and consistently show improved performances by exploiting the strengths and reducing the weaknesses of current methods.
@inproceedings{breuersWACV16,
title={Exploring Bounding Box Context for Multi-Object Tracker Fusion},
author={Breuers, Stefan and Yang, Shishan and Mathias, Markus and Leibe, Bastian},
booktitle={WACV},
year={2016}
}
Previous Year (2015)
