
Profile

|
Publications
DynaMITe: Dynamic Query Bootstrapping for Multi-object Interactive Segmentation Transformer
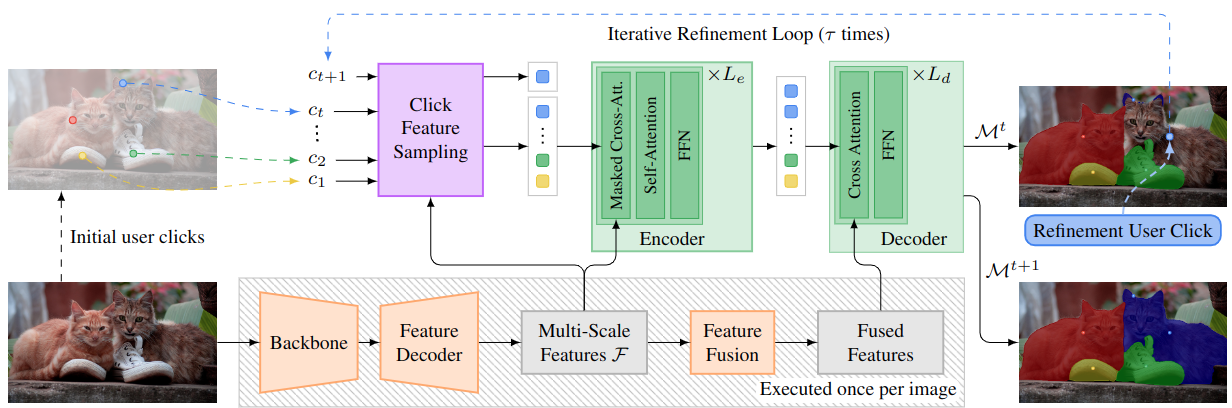
Most state-of-the-art instance segmentation methods rely on large amounts of pixel-precise ground-truth annotations for training, which are expensive to create. Interactive segmentation networks help generate such annotations based on an image and the corresponding user interactions such as clicks. Existing methods for this task can only process a single instance at a time and each user interaction requires a full forward pass through the entire deep network. We introduce a more efficient approach, called DynaMITe, in which we represent user interactions as spatio-temporal queries to a Transformer decoder with a potential to segment multiple object instances in a single iteration. Our architecture also alleviates any need to re-compute image features during refinement, and requires fewer interactions for segmenting multiple instances in a single image when compared to other methods. DynaMITe achieves state-of-the-art results on multiple existing interactive segmentation benchmarks, and also on the new multi-instance benchmark that we propose in this paper.
@article{RanaMahadevan23arxiv,
title={DynaMITe: Dynamic Query Bootstrapping for Multi-object Interactive Segmentation Transformer},
author={Rana, Amit and Mahadevan, Sabarinath and Alexander Hermans and Leibe, Bastian},
journal={arXiv preprint arXiv:2304.06668},
year={2023}
}
Clicks as Queries: Interactive Transformer for Multi-instance Segmentation
Transformers have percolated into a multitude of computer vision domains including dense prediction tasks such as instance segmentation and have demonstrated strong performances. Existing transformer based segmentation approaches such as Mask2Former generate pixel-precise object masks automatically given an input image. While these methods are capable of generating high quality masks in general, they have an inherent class bias and are unable to incorporate user inputs to either segment out-of-distribution classes or to correct bad predictions. Hence, we introduce a novel module called Interactive Transformer that enables transformers to predict and refine objects based on user interactions. Subsequently, we use our Interactive Transformer to develop an interactive segmentation network that can generate mask predictions based on user clicks and thereby widen the transformer application domains within computer vision. In addition, the Interactive Transformer can make such interactive segmentation tasks more efficient by (i) imparting the ability to perform multi-instances segmentation, (ii) alleviating the need to re-compute image-level backbone features as done in existing interactive segmentation networks, and (iii) reducing the required number of user interactions by modeling a common background representation. Our transformer-based architecture outperforms the state-of-the-art interactive segmentation networks on multiple benchmark datasets.
@inproceedings{RanaMahadevan23cvprw,
title={Clicks as Queries: Interactive Transformer for Multi-instance Segmentation},
author={Rana, Amit and Mahadevan, Sabarinath and Alexander Hermans and Leibe, Bastian},
booktitle={CVPRW},
year={2023}
}
