
Profile

|
M.Sc. Ishrat Badami |
Hello, I am a Ph. D. student in Visual Computing Institute. My current research interests are scene understanding and segmentation using Monte Carlo sampling methods.
Publications
3D Semantic Segmentation of Modular Furniture using rjMCMC
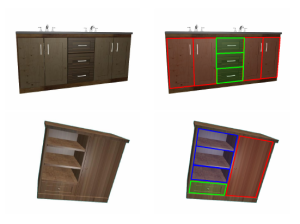
In this paper we propose a novel approach to identify and label the structural elements of furniture e.g. wardrobes, cabinets etc. Given a furniture item, the subdivision into its structural components like doors, drawers and shelves is difficult as the number of components and their spatial arrangements varies severely. Furthermore, structural elements are primarily distinguished by their function rather than by unique color or texture based appearance features. It is therefore difficult to classify them, even if their correct spatial extent were known. In our approach we jointly estimate the number of functional units, their spatial structure, and their corresponding labels by using reversible jump MCMC (rjMCMC), a method well suited for optimization on spaces of varying dimensions (the number of structural elements). Optionally, our system permits to invoke depth information e.g. from RGB-D cameras, which are already frequently mounted on mobile robot platforms. We show a considerable improvement over a baseline method even without using depth data, and an additional performance gain when depth input is enabled.
@inproceedings{badamiWACV17,
title={3D Semantic Segmentation of Modular Furniture using rjMCMC
},
author={Badami, Ishrat and Tom, Manu and Mathias, Markus and Leibe, Bastian},
booktitle={WACV},
year={2017}
}
Semantic Segmentation of Modular Furniture

This paper proposes an approach for the semantic seg- mentation and structural parsing of modular furniture items, such as cabinets, wardrobes, and bookshelves, into so called interaction elements. Such a segmentation into functional units is challenging not only due to the visual similarity of the different elements but also because of their often uniformly colored and low-texture appearance. Our method addresses these challenges by merging structural and appearance likelihoods of each element and jointly op- timizing over shape, relative location, and class labels us- ing Markov Chain Monte Carlo (MCMC) sampling. We propose a novel concept called rectangle coverings which provides a tight bound on the number of structural elements and hence narrows down the search space. We evaluate our approach’s performance on a novel dataset of furniture items and demonstrate its applicability in practice.
@inproceedings{badamiWACV17,
title={Semantic Segmentation of Modular Furniture},
author={Pohlen, Tobias and Badami, Ishrat and Mathias, Markus and Leibe, Bastian},
booktitle={WACV},
year={2016}
}
Multi-Scale, Categorical Object Detection and Pose Estimation using Hough Forest in RGB-D Images

Classification and localization of objects enables a robot to plan and execute tasks in unstructured environments. Much work on the detection and pose estimation of objects in the robotics context focused on object instances. We propose here a novel approach that detects object classes and finds the canonical pose of the detected objects in RGB-D images using Hough forests. In Hough forests each random decision tree maps local image patch to one of its leaves through a cascade of binary decisions over a patch appearance, where each leaf casts probabilistic Hough vote in Hough space encoded in object location, scale and orientation. We propose depth and surfel pair-feature as an additional appearance channels to introduce scale, shape and geometric information about the object. Moreover, we exploit depth at various stages of the processing pipeline to handle variable scale efficiently. Since obtaining large amounts of annotated training data is a cumbersome process, we use training data captured on a turn-table setup. Although the training examples from this domain do not include clutter, occlusions or varying background situations. Hence, we propose a simple but effective approach to render training images from turn-table dataset which shows the same statistical distribution in image properties as natural scenes. We evaluate our approach on publicly available RGB-D object recognition benchmark datasets and demonstrate good performance in varying background and view poses, clutter, and occlusions.
Depth-Enhanced Hough Forests for Object-Class Detection and Continuous Pose Estimation

Much work on the detection and pose estimation of objects in the robotics context focused on object instances. We propose a novel approach that detects object classes and finds the pose of the detected objects in RGB-D images. Our method is based on Hough forests, a variant of random decision and regression trees that categorize pixels and vote for 3D object position and orientation. It makes efficient use of dense depth for scale-invariant detection and pose estimation. We propose an effective way to train our method for arbitrary scenes that are rendered from training data in a turn-table setup. We evaluate our approach on publicly available RGB-D object recognition benchmark datasets and demonstrate stateof-the-art performance in varying background and view poses, clutter, and occlusions.
Material Recognition.
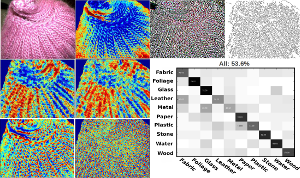
Material recognition is an important subtask in computer vision. In this paper, we aim for the identification of material categories from a single image captured under unknown illumination and view conditions. Therefore, we use several features which cover various aspects of material appearance and perform supervised classification using Support Vector Machines. We demonstrate the feasibility of our approach by testing on the challenging Flickr Material Database. Based on this dataset, we also carry out a comparison to a previously published work [Liu et al., ”Exploring Features in a Bayesian Framework for Material Recognition”, CVPR 2010] which uses Bayesian inference and reaches a recognition rate of 44.6% on this dataset and represents the current state-of the-art. With our SVM approach we obtain 53.1% and hence, significantly outperform this approach.
