
Profile

|
M.Sc. Karim Knaebel |
Publications
DINO in the Room: Leveraging 2D Foundation Models for 3D Segmentation

Vision foundation models (VFMs) trained on large-scale image datasets provide high-quality features that have significantly advanced 2D visual recognition. However, their potential in 3D scene segmentation remains largely untapped, despite the common availability of 2D images alongside 3D point cloud datasets. While significant research has been dedicated to 2D-3D fusion, recent state-of-the-art 3D methods predominantly focus on 3D data, leaving the integration of VFMs into 3D models underexplored. In this work, we challenge this trend by introducing DITR, a generally applicable approach that extracts 2D foundation model features, projects them to 3D, and finally injects them into a 3D point cloud segmentation model. DITR achieves state-of-the-art results on both indoor and outdoor 3D semantic segmentation benchmarks. To enable the use of VFMs even when images are unavailable during inference, we additionally propose to pretrain 3D models by distilling 2D foundation models. By initializing the 3D backbone with knowledge distilled from 2D VFMs, we create a strong basis for downstream 3D segmentation tasks, ultimately boosting performance across various datasets.
@InProceedings{knaebel2025ditr,
title = {{DINO} in the Room: Leveraging {2D} Foundation Models for {3D} Segmentation},
author = {Knaebel, Karim and Yilmaz, Kadir and de Geus, Daan and Hermans, Alexander and Adrian, David and Linder, Timm and Leibe, Bastian},
booktitle = {2026 International Conference on 3D Vision (3DV)},
year = {2026}
}
Fine-Tuning Image-Conditional Diffusion Models is Easier than You Think
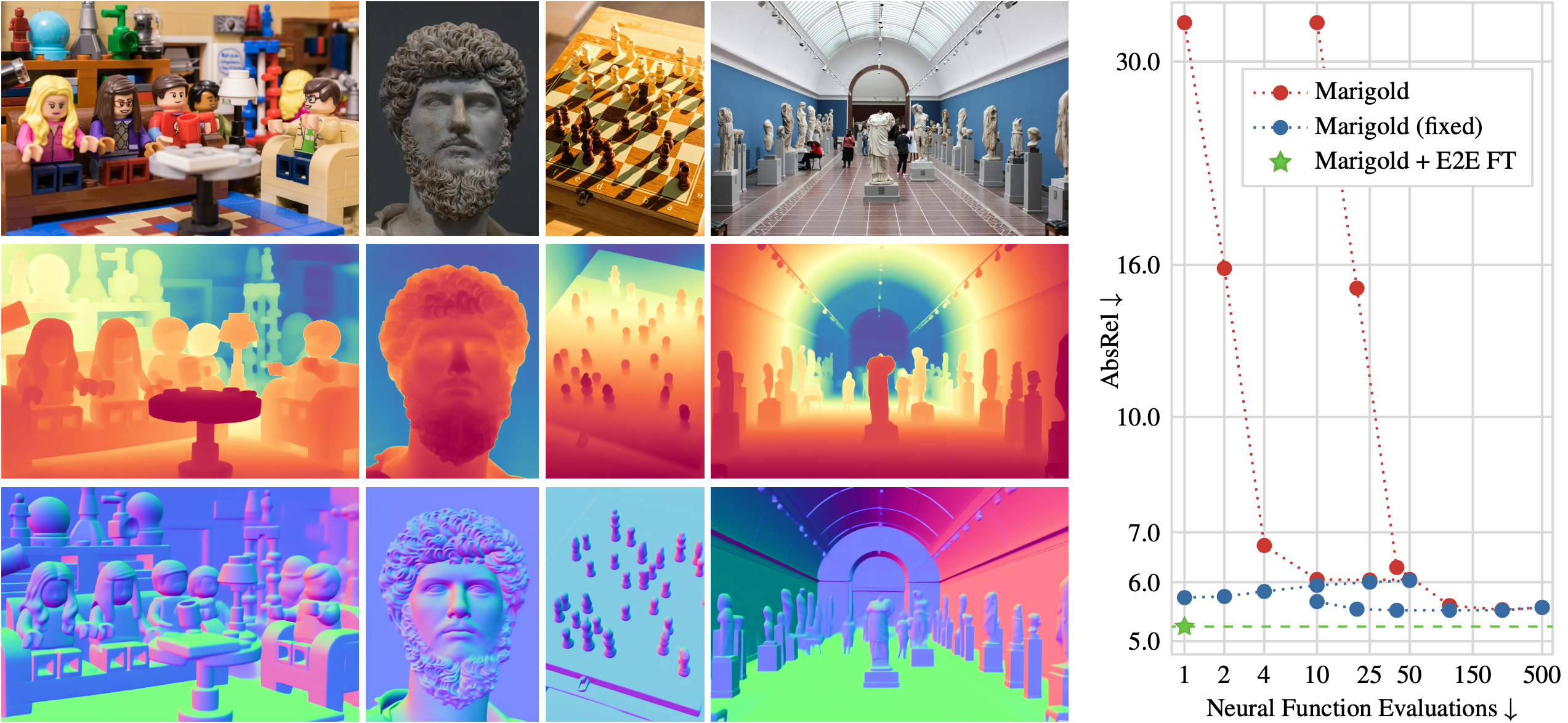
Recent work showed that large diffusion models can be reused as highly precise monocular depth estimators by casting depth estimation as an image-conditional image generation task. While the proposed model achieved state-of-the-art results, high computational demands due to multi-step inference limited its use in many scenarios. In this paper, we show that the perceived inefficiency was caused by a flaw in the inference pipeline that has so far gone unnoticed. The fixed model performs comparably to the best previously reported configuration while being more than 200x faster. To optimize for downstream task performance, we perform end-to-end fine-tuning on top of the single-step model with task-specific losses and get a deterministic model that outperforms all other diffusion-based depth and normal estimation models on common zero-shot benchmarks. We surprisingly find that this fine-tuning protocol also works directly on Stable Diffusion and achieves comparable performance to current state-of-the-art diffusion-based depth and normal estimation models, calling into question some of the conclusions drawn from prior works.
@InProceedings{martingarcia2024diffusione2eft,
title = {Fine-Tuning Image-Conditional Diffusion Models is Easier than You Think},
author = {Martin Garcia, Gonzalo and Knaebel, Karim and Schmidt, Christian and de Geus, Daan and Hermans, Alexander and Leibe, Bastian},
booktitle = {Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)},
year = {2025}
}
Benchmarks and Challenges in Pose Estimation for Egocentric Hand Interactions with Objects

We interact with the world with our hands and see it through our own (egocentric) perspective. A holistic 3Dunderstanding of such interactions from egocentric views is important for tasks in robotics, AR/VR, action recognition and motion generation. Accurately reconstructing such interactions in 3D is challenging due to heavy occlusion, viewpoint bias, camera distortion, and motion blur from the head movement. To this end, we designed the HANDS23 challenge based on the AssemblyHands and ARCTIC datasets with carefully designed training and testing splits. Based on the results of the top submitted methods and more recent baselines on the leaderboards, we perform a thorough analysis on 3D hand(-object) reconstruction tasks. Our analysis demonstrates the effectiveness of addressing distortion specific to egocentric cameras, adopting high-capacity transformers to learn complex hand-object interactions, and fusing predictions from different views. Our study further reveals challenging scenarios intractable with state-of-the-art methods, such as fast hand motion, object reconstruction from narrow egocentric views, and close contact between two hands and objects. Our efforts will enrich the community's knowledge foundation and facilitate future hand studies on egocentric hand-object interactions.
@InProceedings{fan2024hands,
title = {Benchmarks and Challenges in Pose Estimation for Egocentric Hand Interactions with Objects},
author = {Fan, Zicong and Ohkawa, Takehiko and Yang, Linlin and Lin, Nie and Zhou, Zhishan and Zhou, Shihao and Liang, Jiajun and Gao, Zhong and Zhang, Xuanyang and Zhang, Xue and Li, Fei and Liu, Zheng and Lu, Feng and Knaebel, Karim and Leibe, Bastian and On, Jeongwan and Baek, Seungryul and Prakash, Aditya and Gupta, Saurabh and He, Kun and Sato, Yoichi and Hilliges, Otmar and Chang, Hyung Jin and Yao, Angela},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2024}
}
Point2Vec for Self-Supervised Representation Learning on Point Clouds
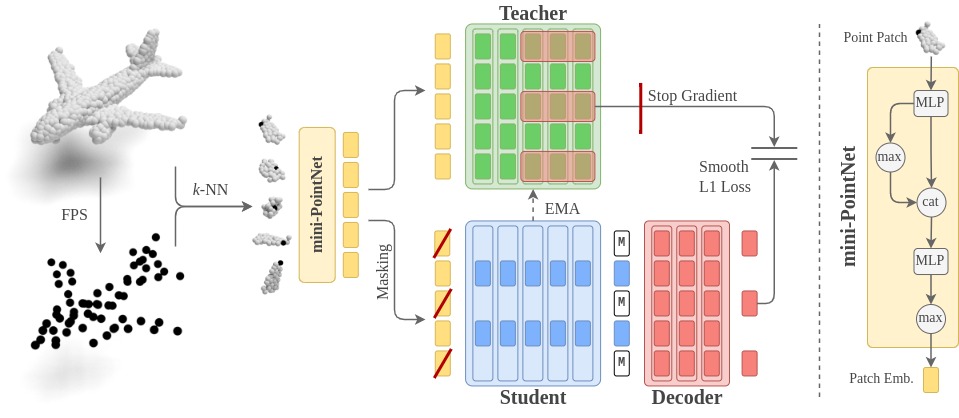
Recently, the self-supervised learning framework data2vec has shown inspiring performance for various modalities using a masked student-teacher approach. However, it remains open whether such a framework generalizes to the unique challenges of 3D point clouds.To answer this question, we extend data2vec to the point cloud domain and report encouraging results on several downstream tasks. In an in-depth analysis, we discover that the leakage of positional information reveals the overall object shape to the student even under heavy masking and thus hampers data2vec to learn strong representations for point clouds. We address this 3D-specific shortcoming by proposing point2vec, which unleashes the full potential of data2vec-like pre-training on point clouds. Our experiments show that point2vec outperforms other self-supervised methods on shape classification and few-shot learning on ModelNet40 and ScanObjectNN, while achieving competitive results on part segmentation on ShapeNetParts. These results suggest that the learned representations are strong and transferable, highlighting point2vec as a promising direction for self-supervised learning of point cloud representations.
@InProceedings{knaebel2023point2vec,
title = {Point2Vec for Self-Supervised Representation Learning on Point Clouds},
author = {Knaebel, Karim and Schult, Jonas and Hermans, Alexander and Leibe, Bastian},
journal = {German Conference on Pattern Recognition (GCPR)},
year = {2023}
}
