
Profile

|
M.Sc. Christian Schmidt |
Publications
Fine-Tuning Image-Conditional Diffusion Models is Easier than You Think
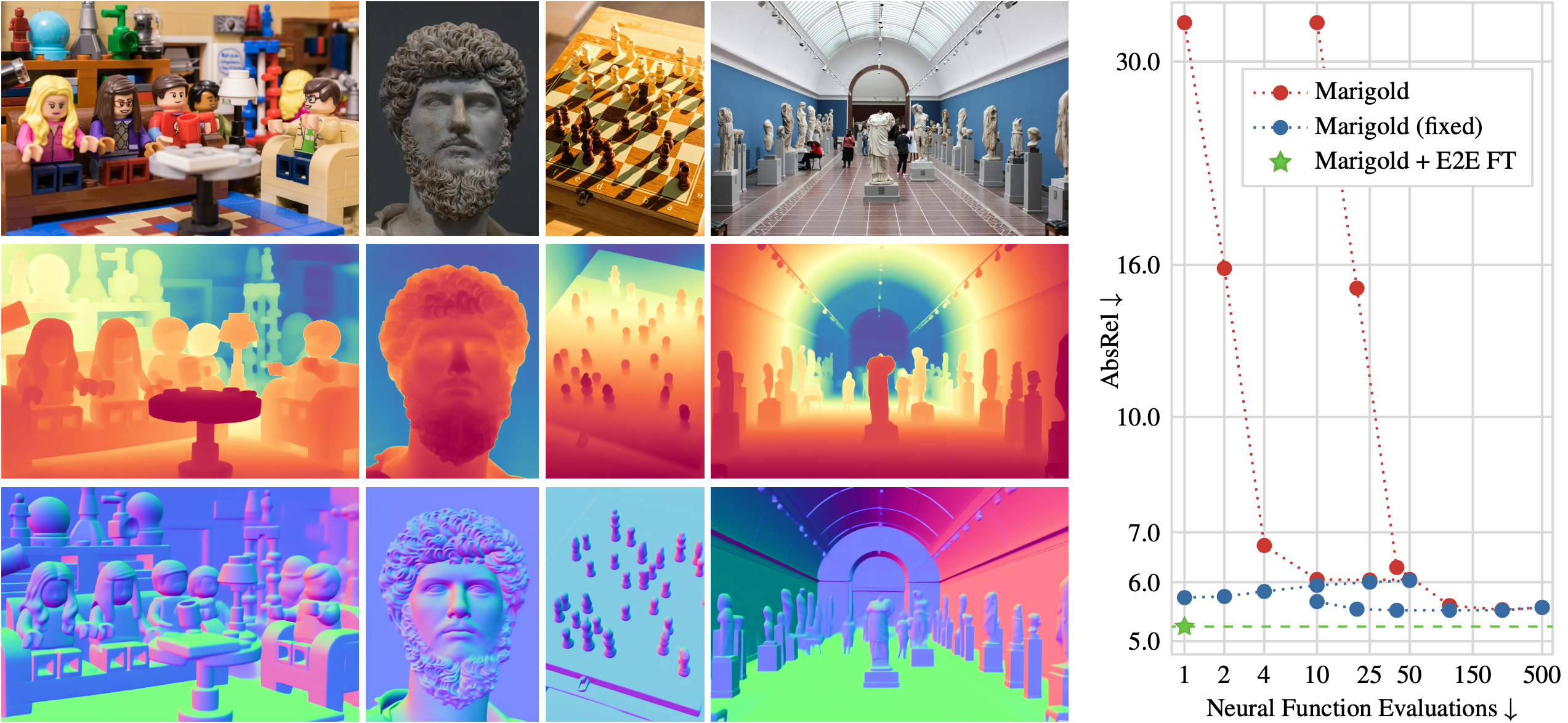
Recent work showed that large diffusion models can be reused as highly precise monocular depth estimators by casting depth estimation as an image-conditional image generation task. While the proposed model achieved state-of-the-art results, high computational demands due to multi-step inference limited its use in many scenarios. In this paper, we show that the perceived inefficiency was caused by a flaw in the inference pipeline that has so far gone unnoticed. The fixed model performs comparably to the best previously reported configuration while being more than 200x faster. To optimize for downstream task performance, we perform end-to-end fine-tuning on top of the single-step model with task-specific losses and get a deterministic model that outperforms all other diffusion-based depth and normal estimation models on common zero-shot benchmarks. We surprisingly find that this fine-tuning protocol also works directly on Stable Diffusion and achieves comparable performance to current state-of-the-art diffusion-based depth and normal estimation models, calling into question some of the conclusions drawn from prior works.
@InProceedings{martingarcia2024diffusione2eft,
title = {Fine-Tuning Image-Conditional Diffusion Models is Easier than You Think},
author = {Martin Garcia, Gonzalo and Knaebel, Karim and Schmidt, Christian and de Geus, Daan and Hermans, Alexander and Leibe, Bastian},
booktitle = {Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)},
year = {2025}
}
Look Gauss, No Pose: Novel View Synthesis using Gaussian Splatting without Accurate Pose Initialization
3D Gaussian Splatting has recently emerged as a powerful tool for fast and accurate novel-view synthesis from a set of posed input images. However, like most novel-view synthesis approaches, it relies on accurate camera pose information, limiting its applicability in real-world scenarios where acquiring accurate camera poses can be challenging or even impossible. We propose an extension to the 3D Gaussian Splatting framework by optimizing the extrinsic camera parameters with respect to photometric residuals. We derive the analytical gradients and integrate their computation with the existing high-performance CUDA implementation. This enables downstream tasks such as 6-DoF camera pose estimation as well as joint reconstruction and camera refinement. In particular, we achieve rapid convergence and high accuracy for pose estimation on real-world scenes. Our method enables fast reconstruction of 3D scenes without requiring accurate pose information by jointly optimizing geometry and camera poses, while achieving state-of-the-art results in novel-view synthesis. Our approach is considerably faster to optimize than most com- peting methods, and several times faster in rendering. We show results on real-world scenes and complex trajectories through simulated environments, achieving state-of-the-art results on LLFF while reducing runtime by two to four times compared to the most efficient competing method. Source code will be available at https://github.com/Schmiddo/noposegs.
